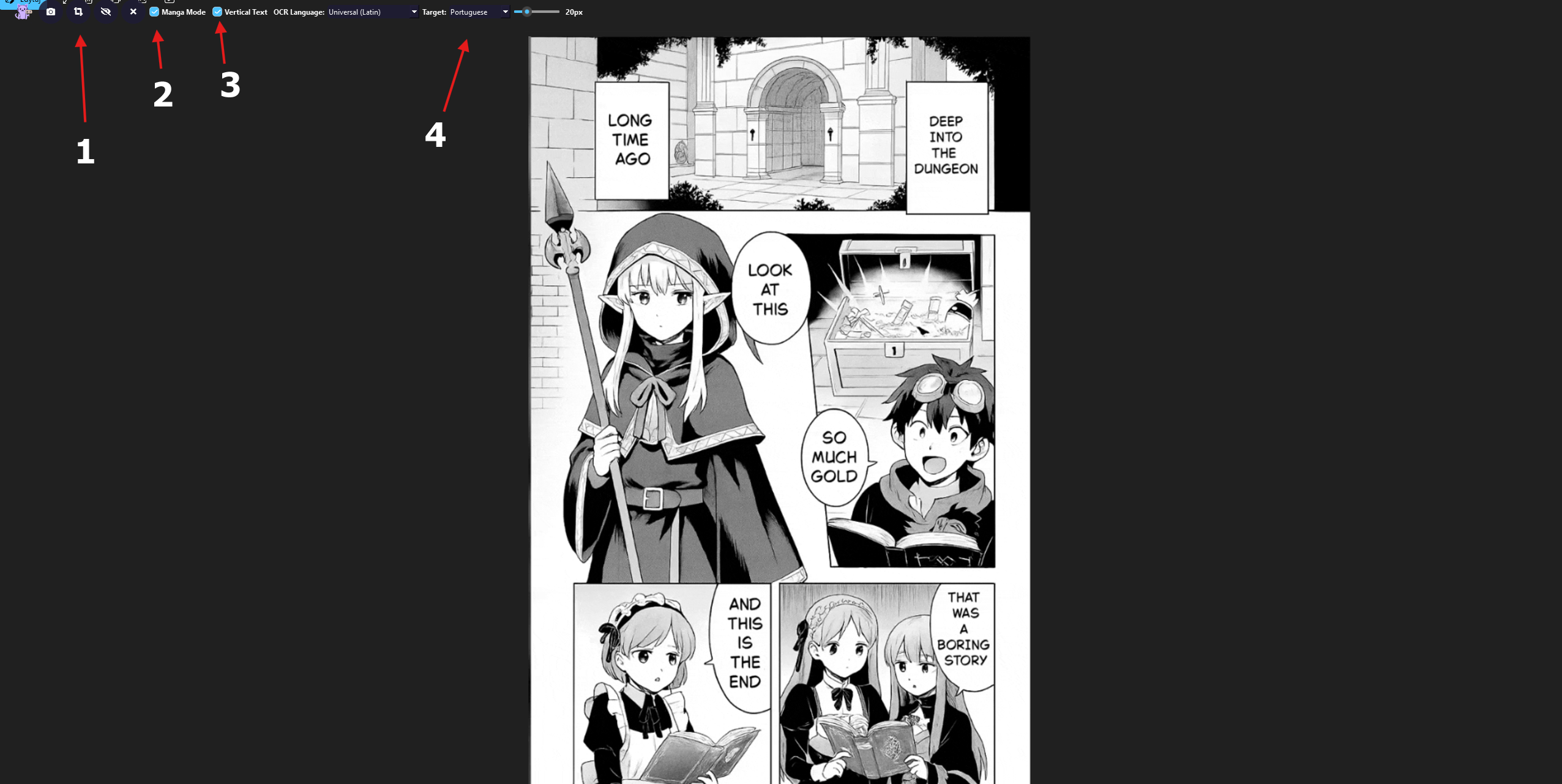
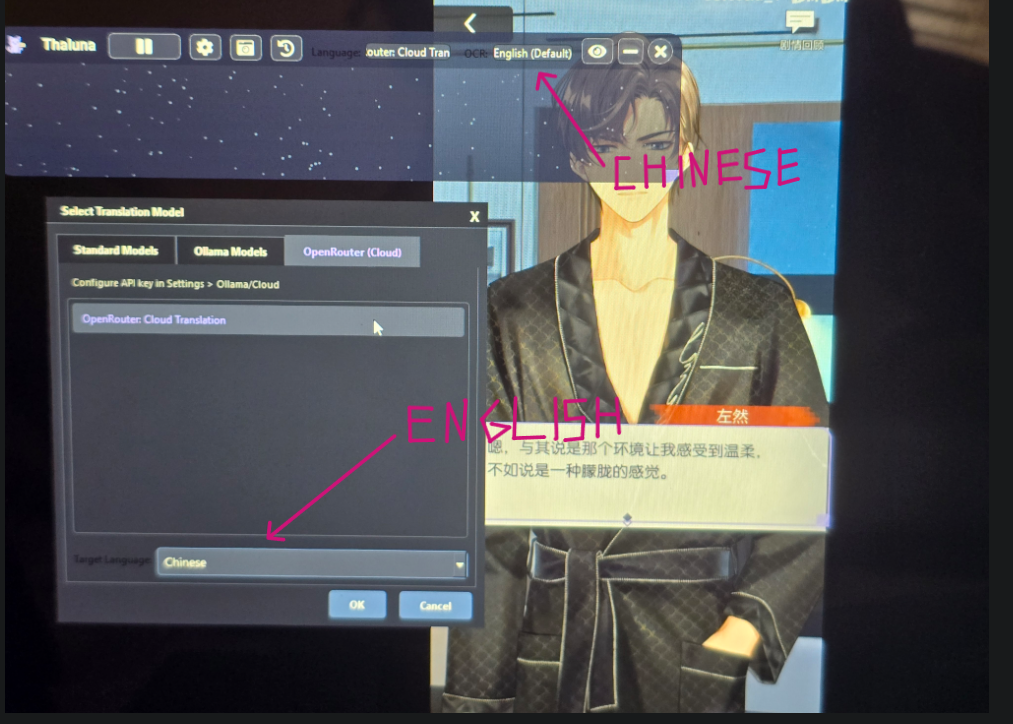
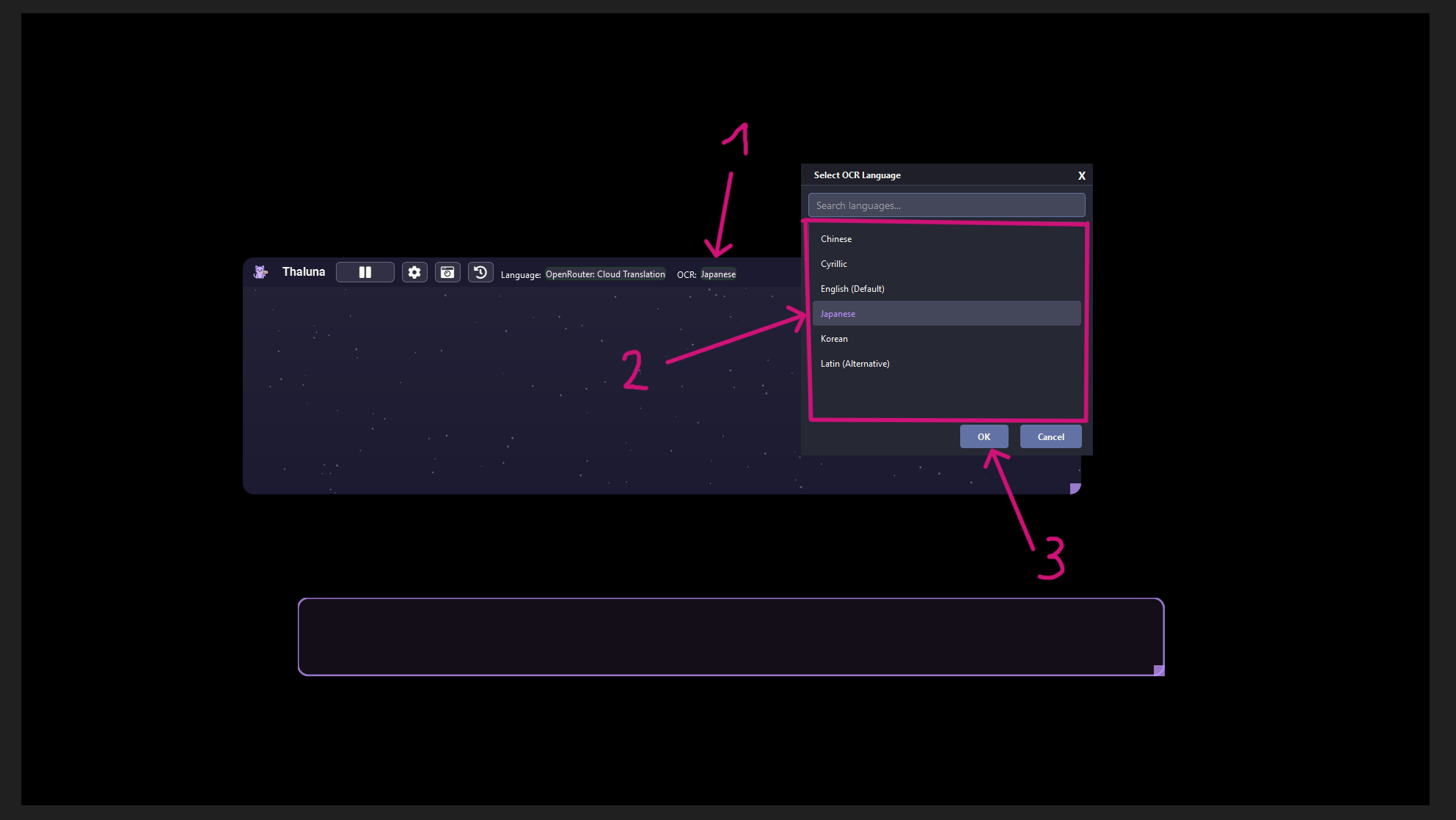
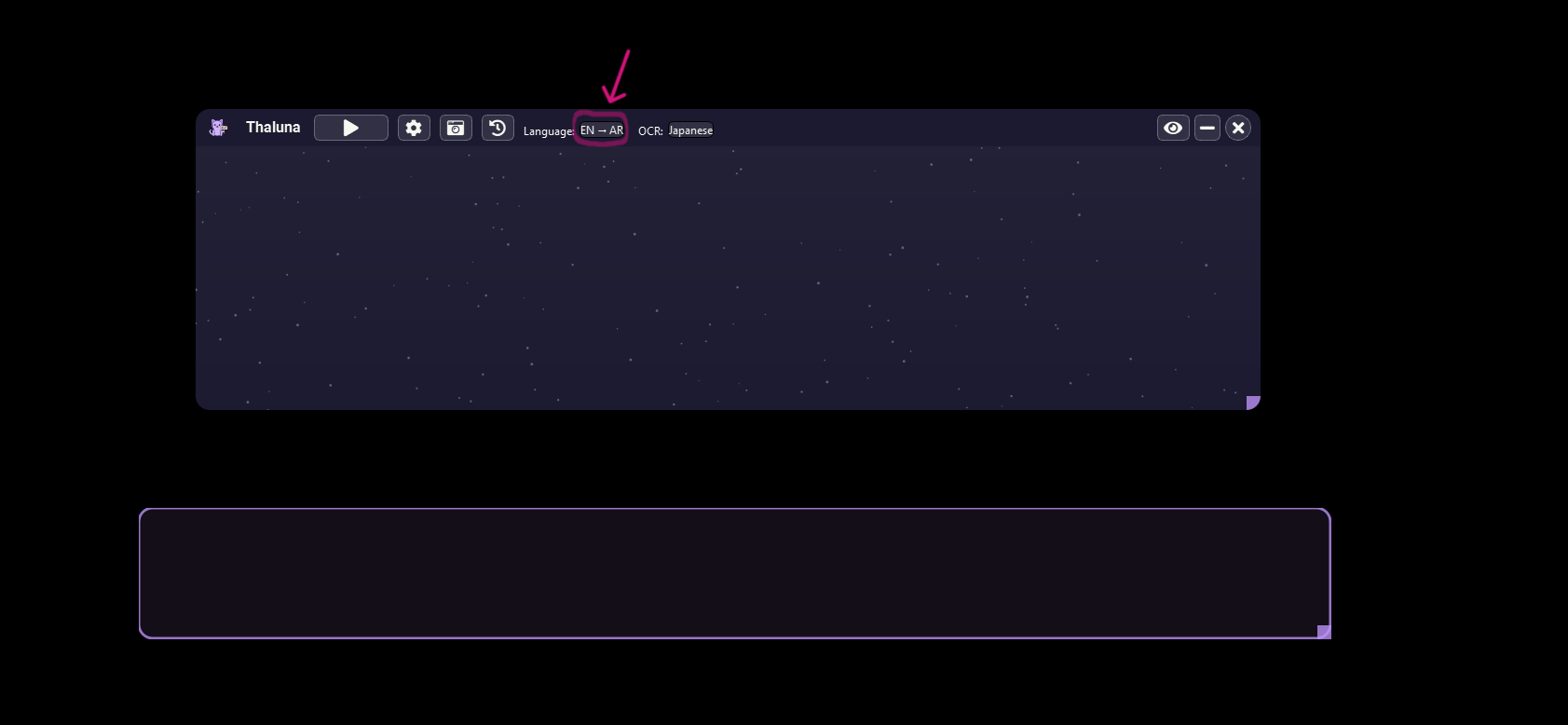
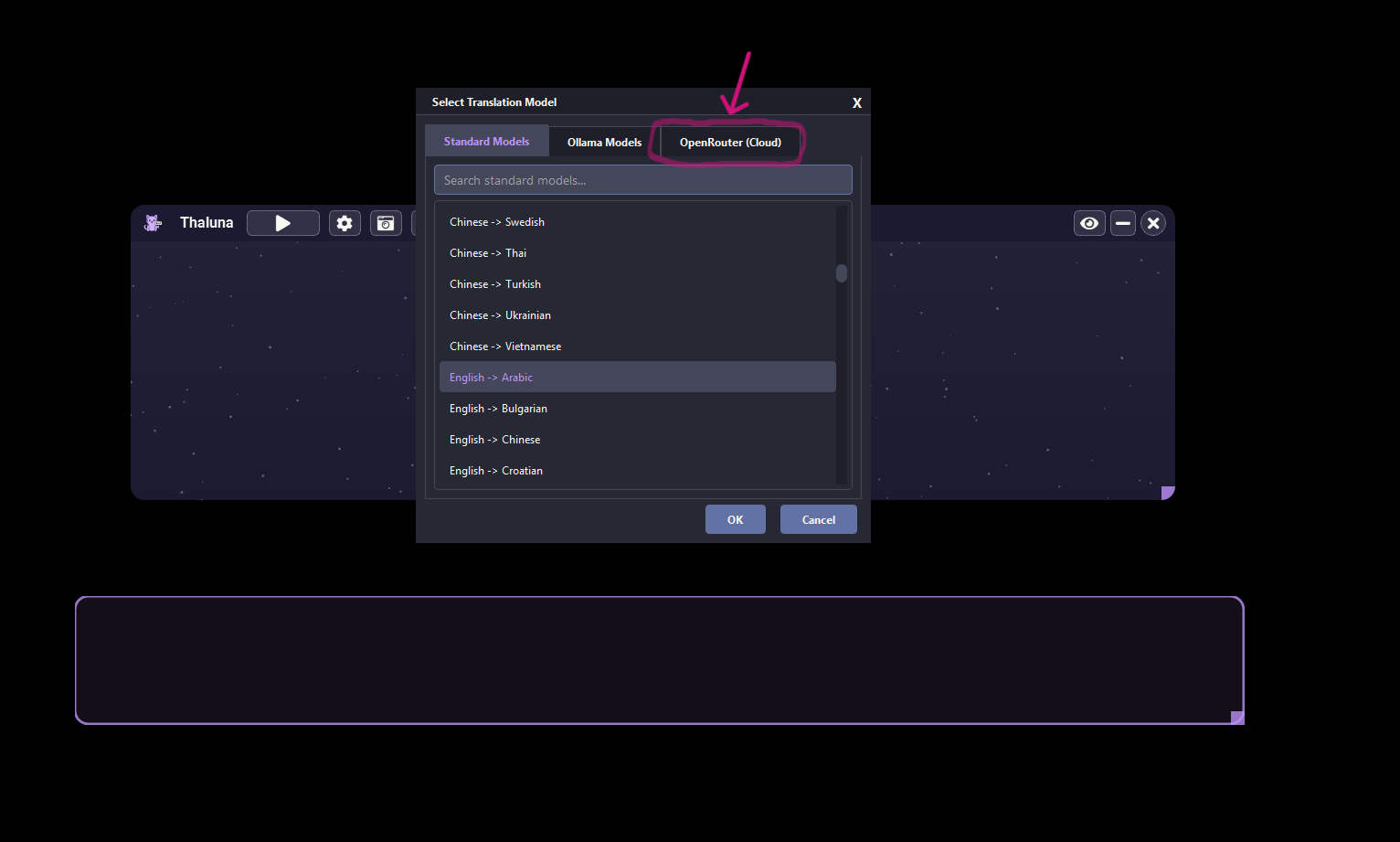
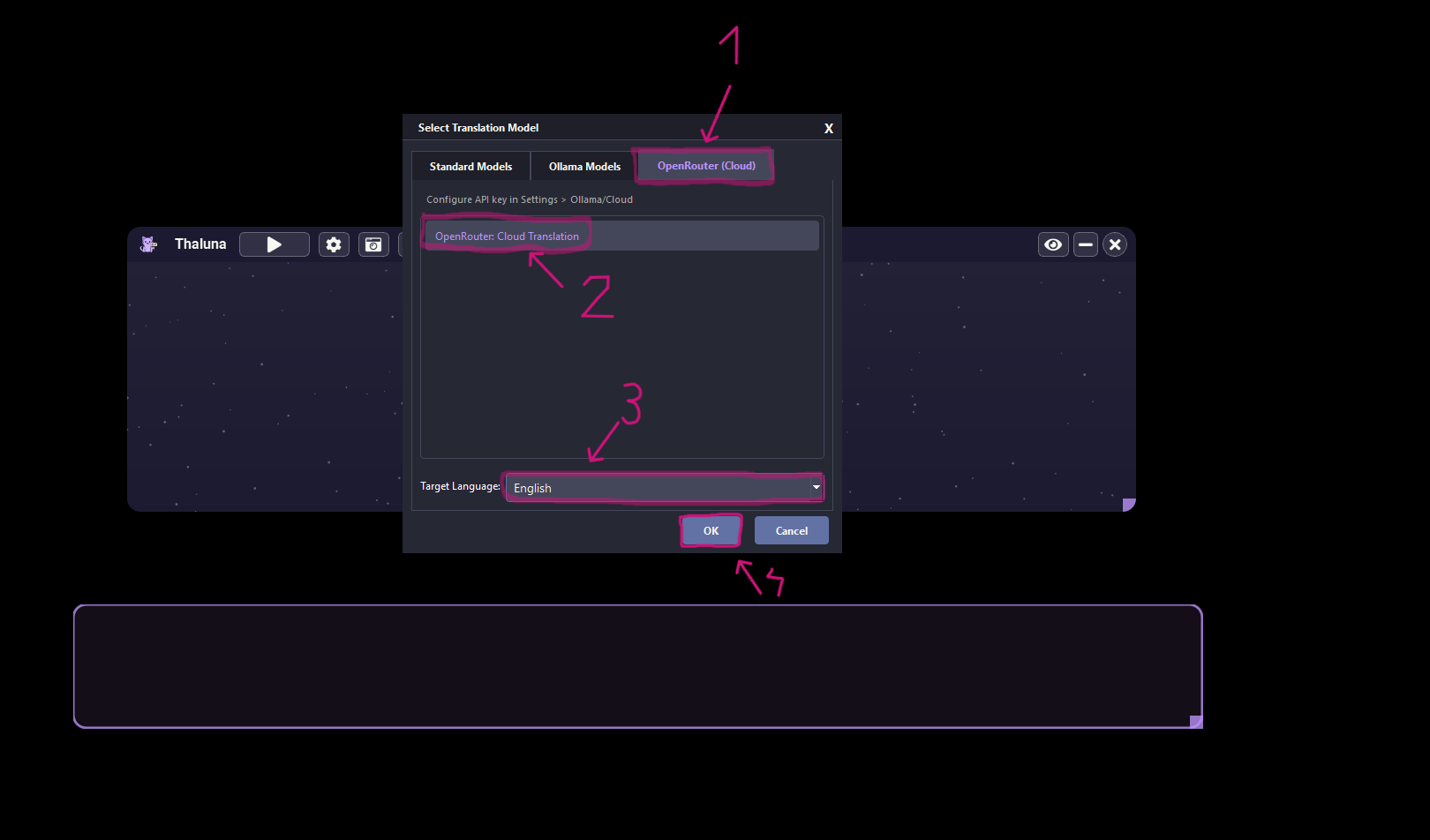
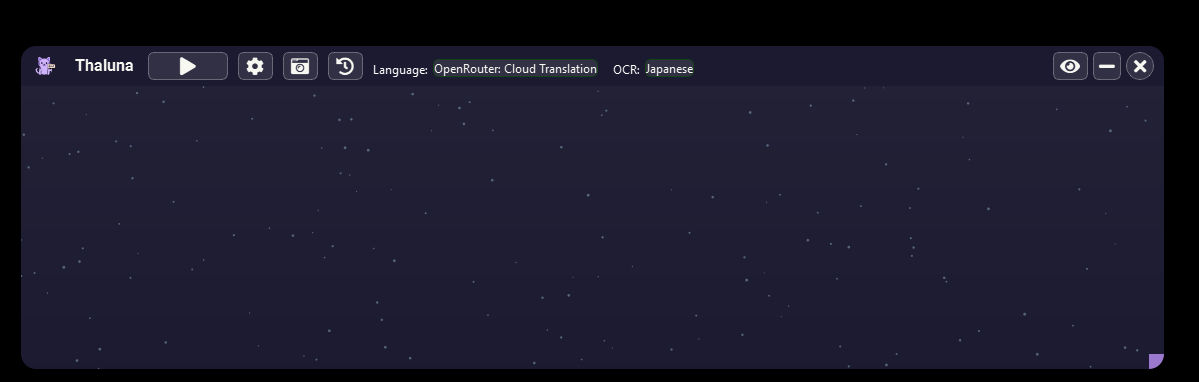
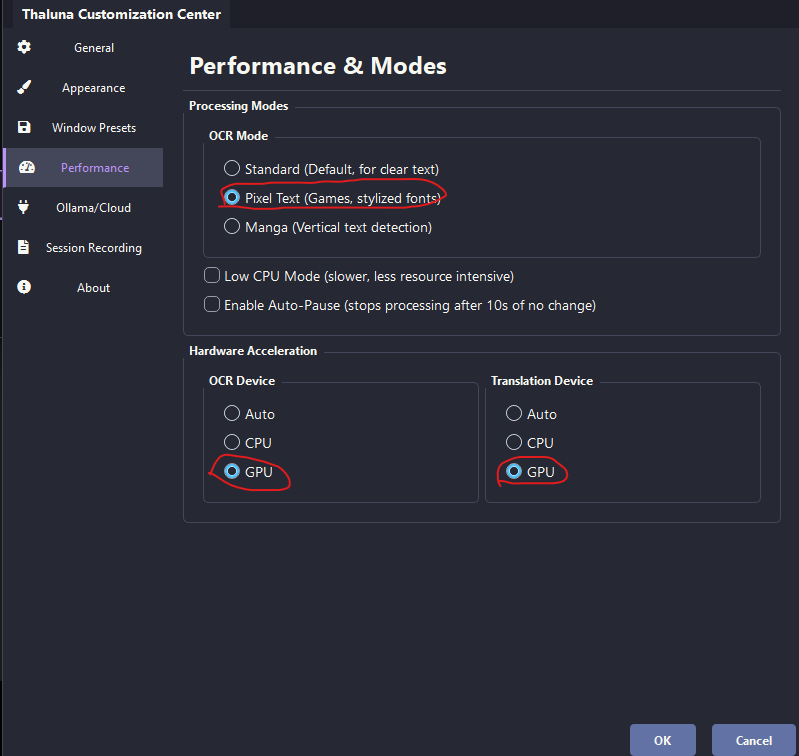
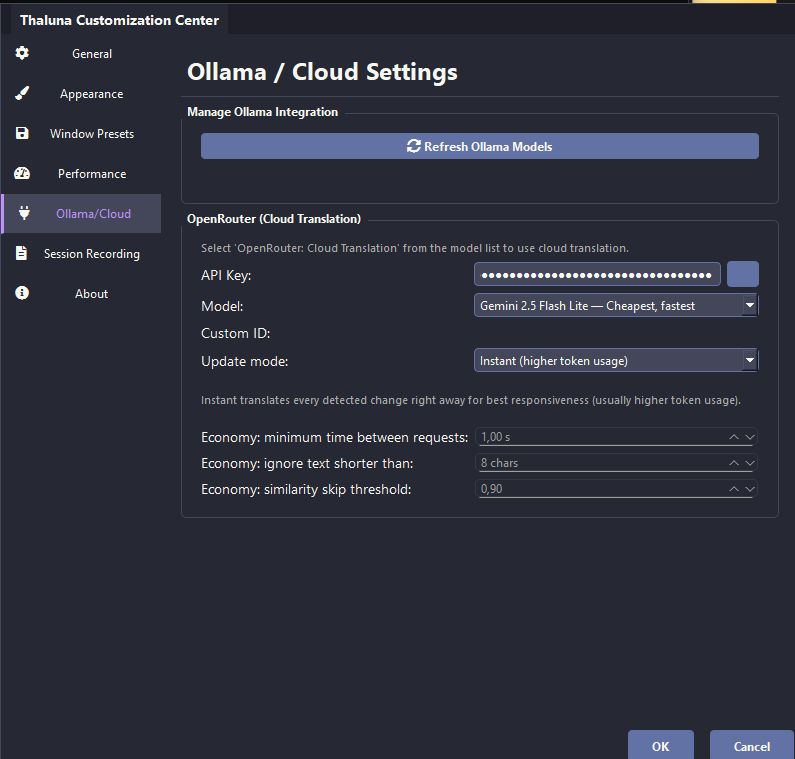
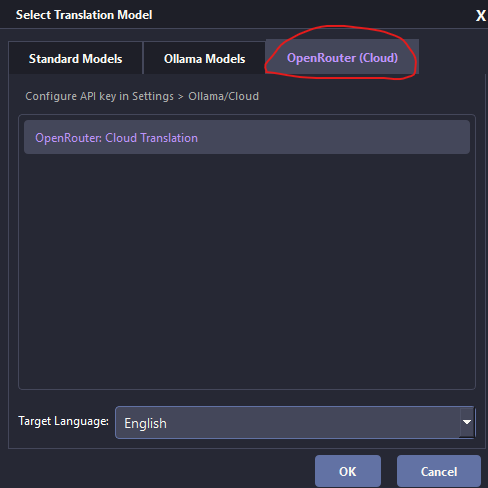
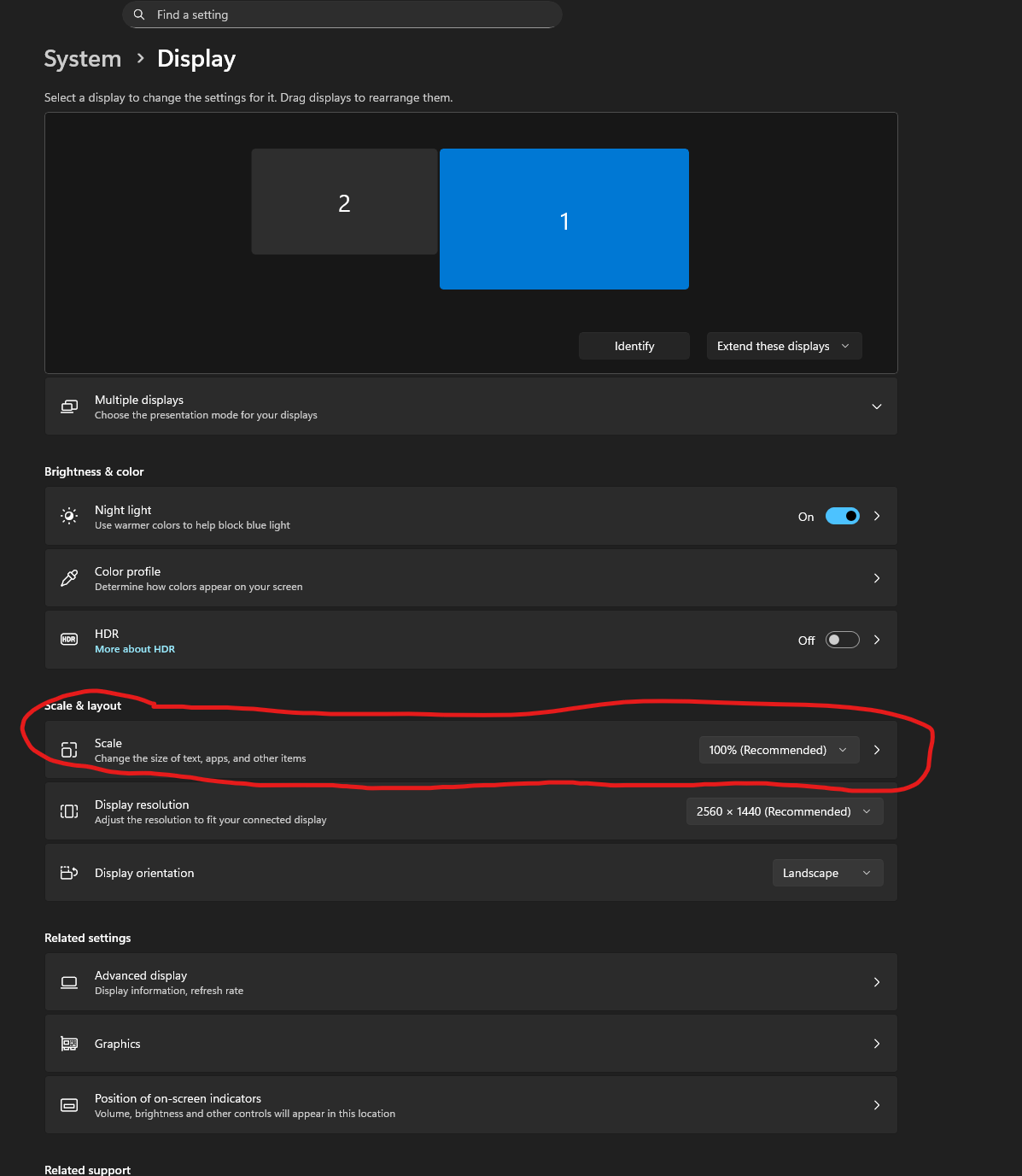
Hi! Thanks for asking.
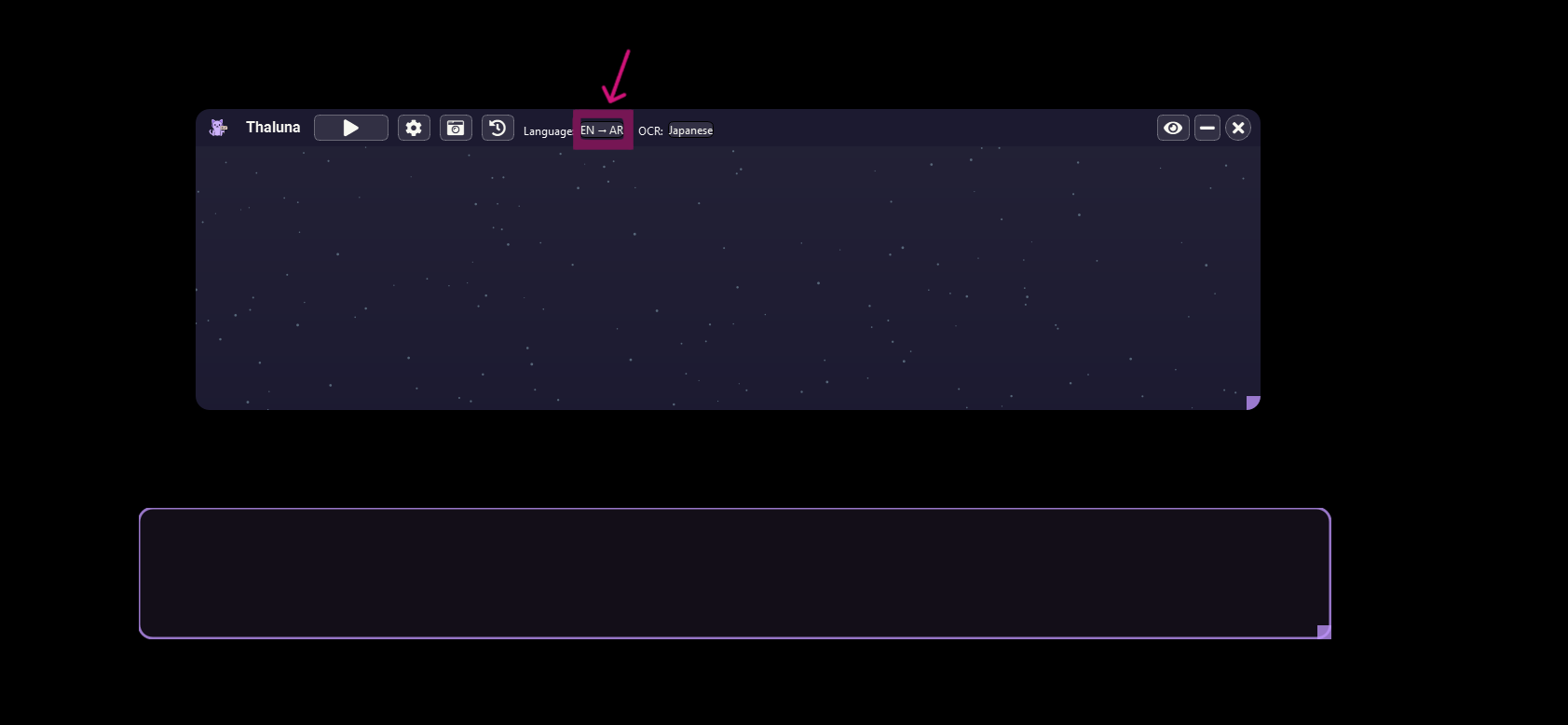
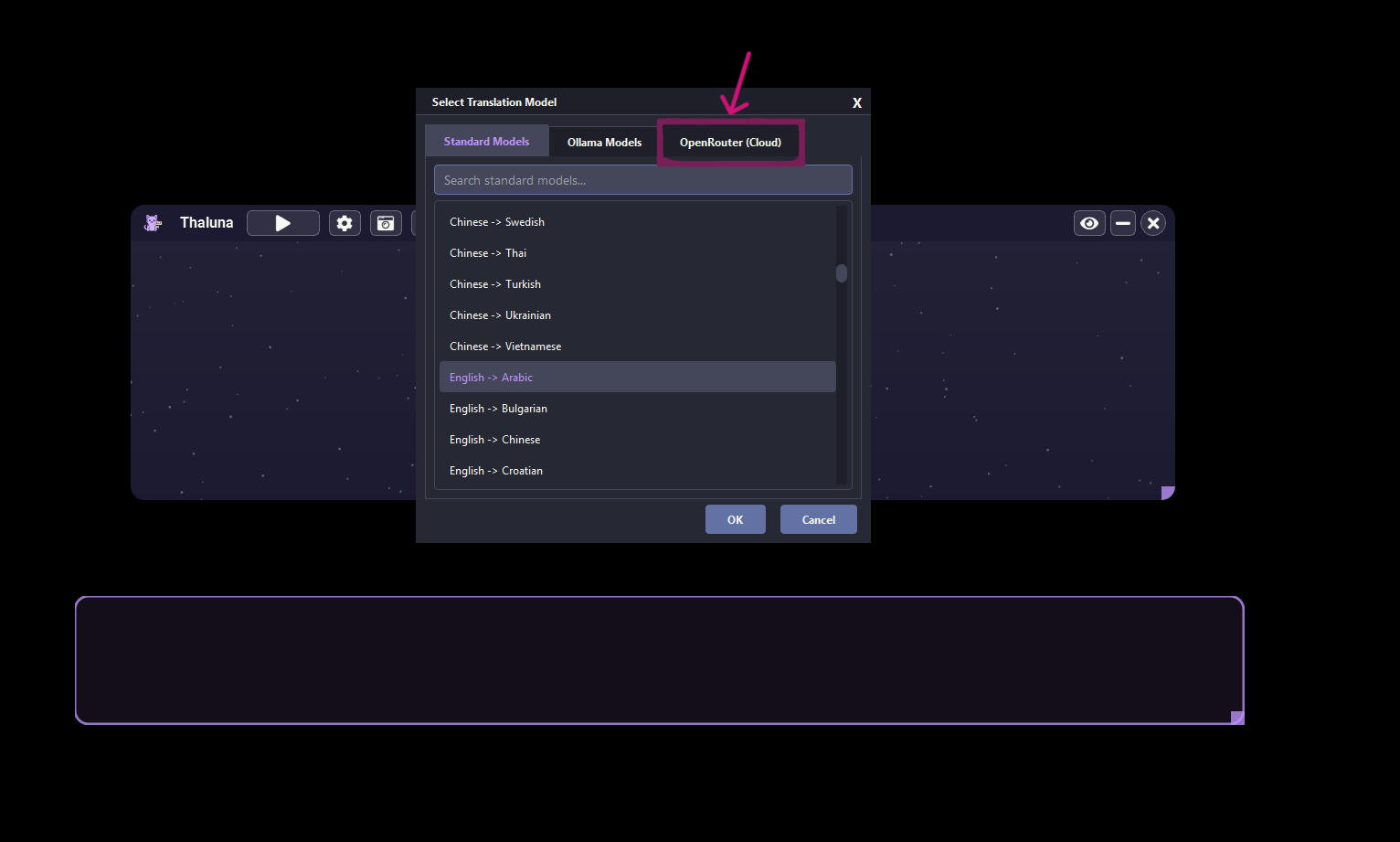
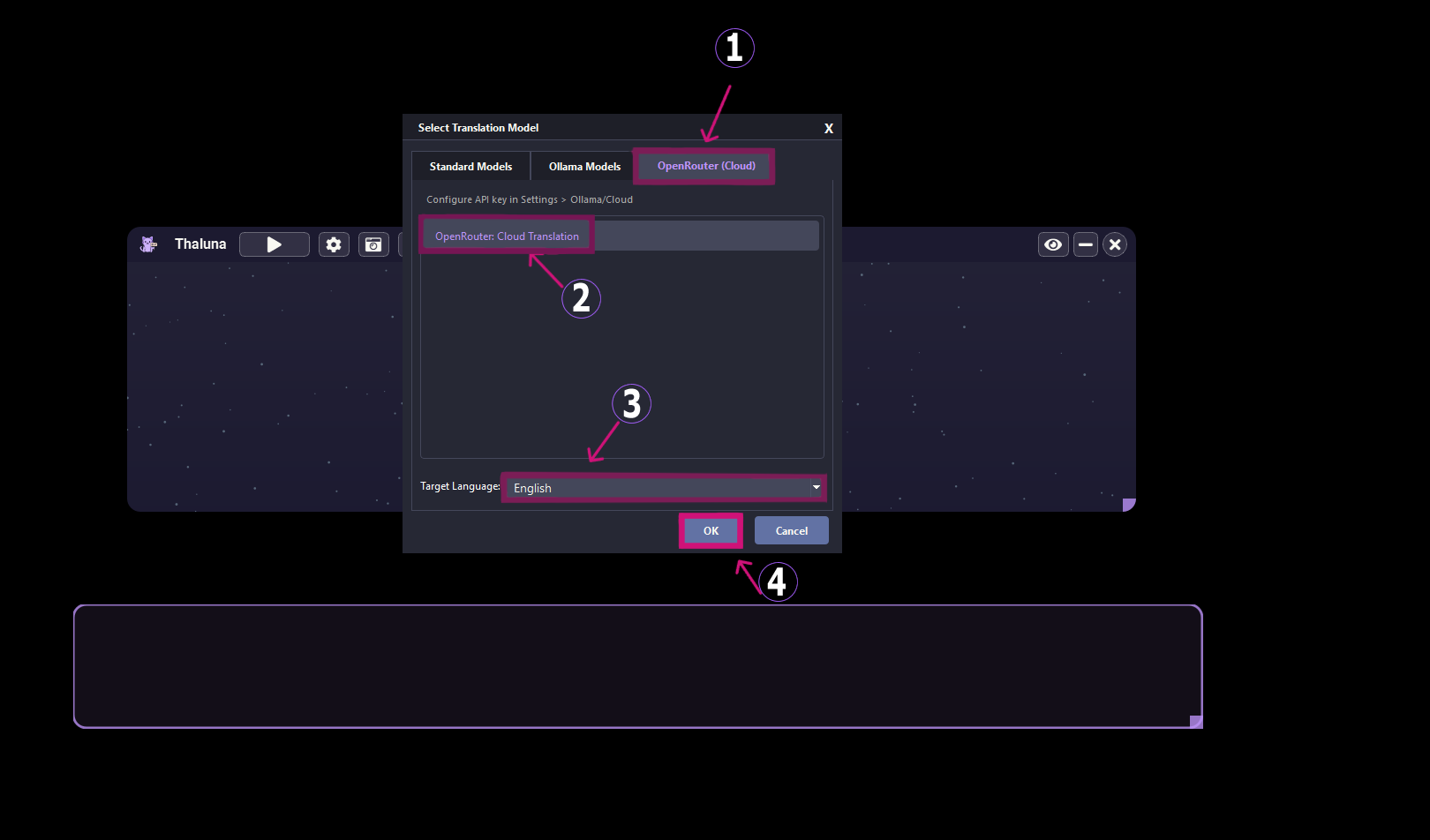
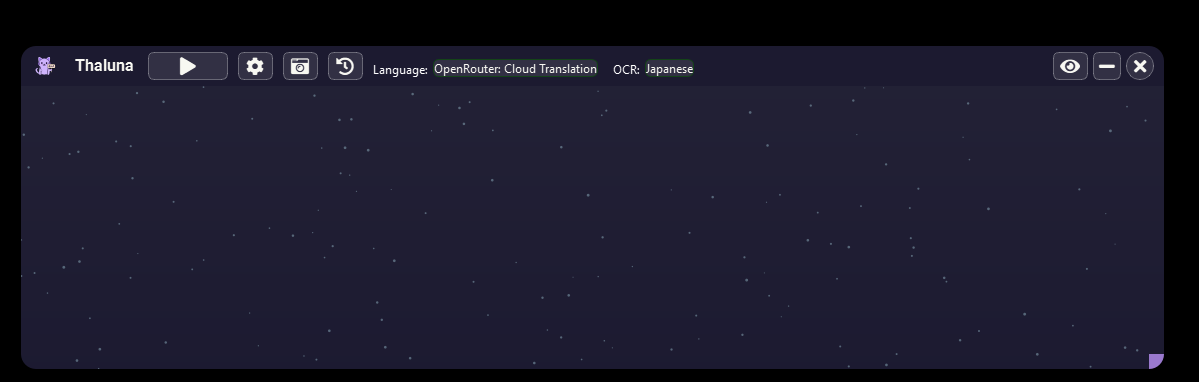
Both the Demo and Full versions of Thaluna are currently unsigned.
I do not currently plan to purchase a commercial Authenticode certificate, as trusted code signing involves recurring fees and publisher verification that are not financially viable for a $1.99 independent application.
Thank you for understanding.