I went ahead and made a video of the whole process.
You can find the video here: "Stream Friendly". I couldn't upload it directly since it only allows a maximum of 3MB. I've also included some screenshots below to help explain what's happening.
Stream Friendly: Here are the bugs I spotted in the video:
1. Some bubbles are translated well. But sometimes the original text peeks out a little at the edges, or there's a small gray spot.


2. Similar to the first point, the text translates nicely and the sentence makes sense, but unfortunately, one or more original words pop up underneath the translated text, making it really hard to read. The original text peeks out at the edges here too.


3. There's a word recognition bug where it can't figure out some words, so it gives a nonsense translation and the original word or text is still visible. I wonder if the manga's font is the issue?



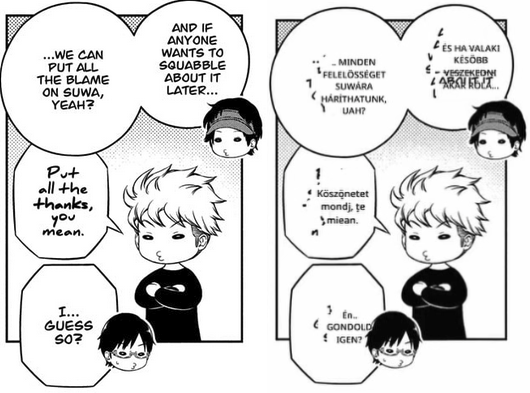
4. It's like the first, but the sentence doesn't make sense because it used the English word itself instead of its Hungarian equivalent.

It contains the letter "i," but essentially, it is the English word "mean."
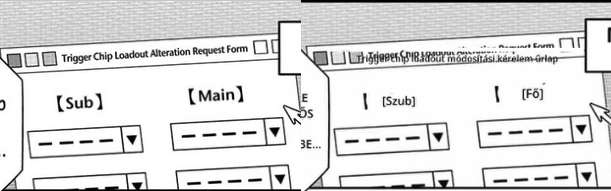
5. The app can't properly translate text that's on background images inside the manga panel, outside of the bubbles.

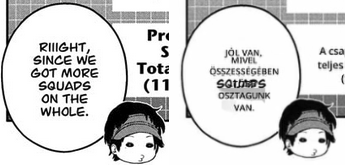
6. In some places where there are two words one under another, short one-word sentences, it translates nonsensical sentences. To be more accurate, this was a really literal translation. Maybe because they're too short?

I first tried the Gemini API, but manga translation just didn't work. It gave me a '429 too many requests' error. So I used Azure AI for the translation instead because I didn't want to burn through my DeepL character count, even though it resets in a week. Despite that, I decided to redo the video with Deepl this time lol because I realized that even if DXGI doesn't work, I can record with WGC. So I made a video using that method too.
WGC: "Video link"
The translation in the video is flashing and flickering because of that yellow border, but you can still read it if you pause it. I'm not sure why it's doing that in the video, because everything looked completely normal on my screen while I was recording.
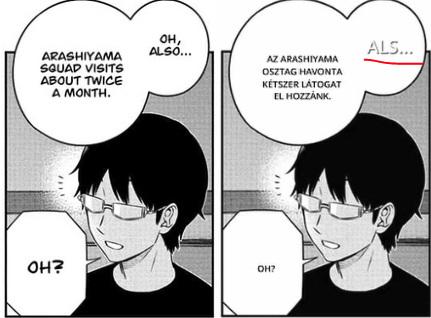
Bugs in the video: From what I could tell, the bugs are about the same as the ones with Stream Friendly, except for the issue with the original text peeking out at the edges that wasn't happening here. I also noticed a new bug here: Sometimes it doesn't translate the whole sentence, just shows a single word.
1. Some bubbles are translated well. But there's a small gray spot.

2. Similar to the first point, the text translates nicely and the sentence makes sense, but unfortunately, one or more original words pop up underneath the translated text, making it really hard to read.

3. There's a word recognition bug where it can't figure out some words, so it gives a nonsense translation and the original word or text is still visible. I wonder if the manga's font is the issue?



4. It's like the first, but the sentence doesn't make sense because it used the English word itself instead of its Hungarian equivalent.
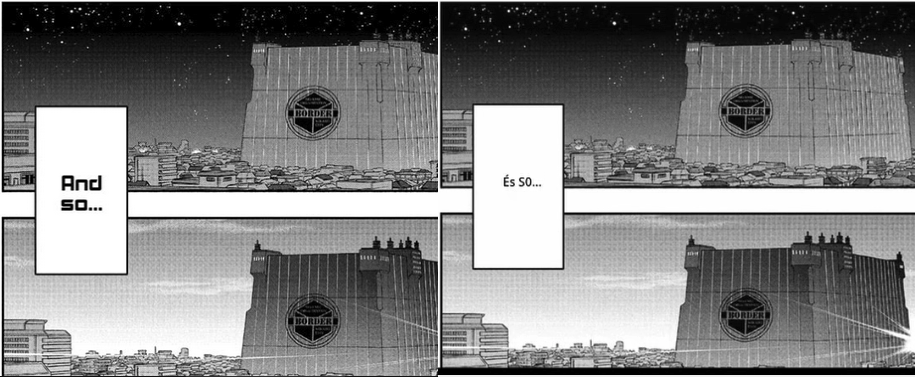
5. The app can't properly translate text that's on background images inside the manga panel, outside of the bubbles.

6. In some places where there are two words one under another, short one-word sentences, it translates nonsensical sentences. To be more accurate, this was a really literal translation. This was a little better, but it's still not quite right. Maybe because they're too short?

7. Sometimes it doesn't translate the whole sentence, just shows a single word.
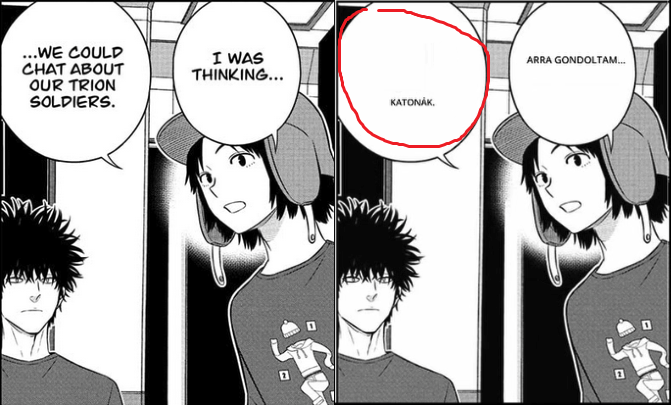
Oh, I almost forgot, but I also gave MangaOCR a try. The Japanese-to-Hungarian translation with DeepL wasn't the best, but it was acceptable. At least with MangaOCR, everything looked pretty okay. The translation was really slow, though. I had to wait at least a minute for it to finish. I edited the video to cut out all those waiting periods. Since I was already making videos, I made a short one for this too, but only with WGC because it doesn't have the text poking out at the edges issue, though it did have the flashing. You can find that one here: "Link".
I did find one bug with MangaOCR: it doesn't work with a Custom API. When I switch to a Custom API and then try to select MangaOCR, the app just freezes. It works fine with all the other translation engines.
So that's all the feedback I have for now.