Hi, I came across a project similar to what you’re looking for: LLPlayer. It’s designed for videos rather than gaming, but it works really well. It’s especially useful if you watch anime, since it generates subtitles using AI.
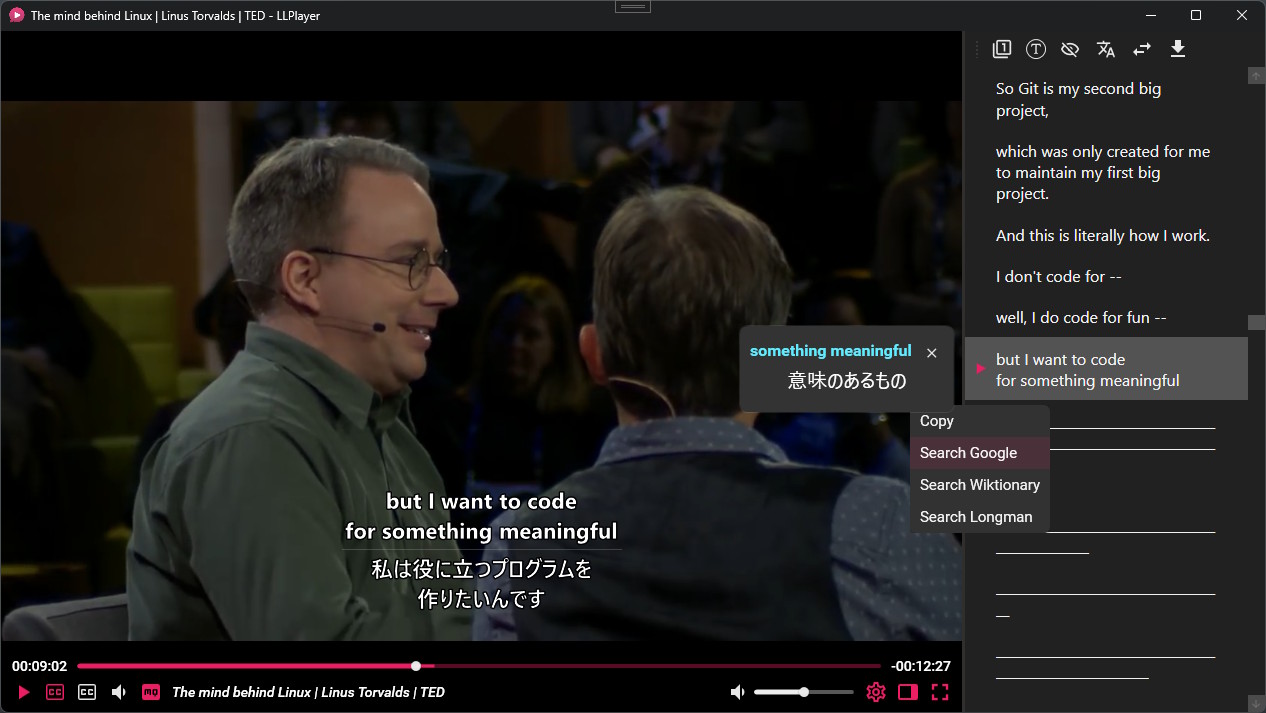
LLPlayer has many features for language learning that are not available in normal video players.
- Dual Subtitles: Two subtitles can be displayed simultaneously. Both text subtitles and bitmap subtitles are supported.
- AI-generated subtitles (ASR): Real-time automatic subtitle generation from any video and audio, powered by OpenAI Whisper. two engines whisper.cpp and faster-whisper are supported.
- Real-time Translation: Supports many translation engines, such as Google, DeepL, Ollama, LM Studio, OpenAI.
- Context-aware Translation: Highly accurate translation by recognizing the context of subtitles using LLM.
- Real-time OCR subtitles: Can convert bitmap subtitles to text subtitles in real time, powered by Tesseract OCR and Microsoft OCR.
- Subtitles Sidebar: Both text and bitmap are supported. Seek and word lookup available. Also supports incremental subtitle search.
- Instant word lookup: Word lookup and browser searches can be performed on subtitle text.
- Customizable Browser Search: Browser searches can be performed from the context menu of a word, and the search site can be completely customized.
- Plays online videos: With yt-dlp integration, any online video can be played back in real time, with AI subtitle generation, word lookups!
- Flexible Subtitles Size/Placement Settings: The size and position of the dual subtitles can be adjusted very flexibly.
- Subtitles Seeking for any format: Any subtitle format can be used for subtitle seek.
- Built-in Subtitles Downloader: Supports opensubtitles.org
- Integrate with browser extensions: Can work with any browser extensions, such as Yomitan and 10ten.
- Customizable Dark Theme: The theme is based on black and can be customized.
- Fully Customizable Shortcuts: All keyboard shortcuts are fully customizable. The same action can be assigned to multiple keys!
- Built-in Cheat Sheet: You can find out how to use the application in the application itself.
- Free, Open Source, Written in C#: Written in C#/WPF, not C, so customization is super easy!