
Very cute novel. Absolutely in love with all the characters. Every scene I had a new favourite !!!
A member registered Oct 16, 2016 · View creator page →
Creator of

Take your freight to the next level -- outer space! Classic arcade game style.

All-In-One Solution for Object Instantiation in Unity -- from level design to active projectiles !

Something about depression and hope.
Recent community posts
Super Text Mesh community · Posted in [SOLVED][Suggesion/Feature Request]Extended Features for Quads + Project-Wide Asset Search
Hey !
Thank you SO MUCH for all this. I think this shall work fantastically !

It's been absolutely fun seeing how all this works and getting help with something so absurd (but possibly versatile ?!). Thank you so much for everything !
I think, aside from the to-be audio readouts of quads, everything is done ! Can't wait for the next update and new features and improvements. You seriously rock. I gave a lot of this my own try between replies and it's been cool to see different approaches and solutions to problems. I think I'll be using this all to make some powerful games in the future. ✨✨
Thank you again. Sorry this was such a hassle ! If you have any more questions or otherwise, I'm all ears, and I'll be eager to give you the same when I have them again.
Good luck and take care
Super Text Mesh community · Posted in [SOLVED][Suggesion/Feature Request]Extended Features for Quads + Project-Wide Asset Search
Hello!
You know, I have no idea how I missed "STM Sound Clips" as a feature, but that may work for the audio portion of things ! At least for non-quad text. As for the graphics portion with quads, let's say I want to map all this to a kind of "voice"...

So instead of doing "<c=secret-color-CHMRW><q=secret-glyph-FGHIJ></c><c=secret-color-EJOTY><q=secret-glyph-ABCDE></c>" (produces 'HE' in 'HELLO WORLD') etcetera in the text inspector I could instead map it to a kind of "voice" that automates the colour assignment and glyph appearance. In this example, the glyphs could be animated for a "hand-drawn" effect or equate to garbled "dream" speech. Then in addition (or as a replacement to animated glyphs) they could be animated however they might for read-out (wiggling, jiggling, squishing, etc). These effects in combination with the STMSoundClips would be perfect for earlier-mentioned scenarios.
EDIT: I am noticing that using the context menu to create a Sound Clip Data asset seems to instead create an 'STMAutoClipData' instead of 'STMSoundClipData'. Additionally, there's no 'Auto Clip Data' in the context menu to choose from. All other types seem to create the proper data.
Super Text Mesh community · Created a new topic [SOLVED][BUG] STM Reads out while game (in-editor) is paused
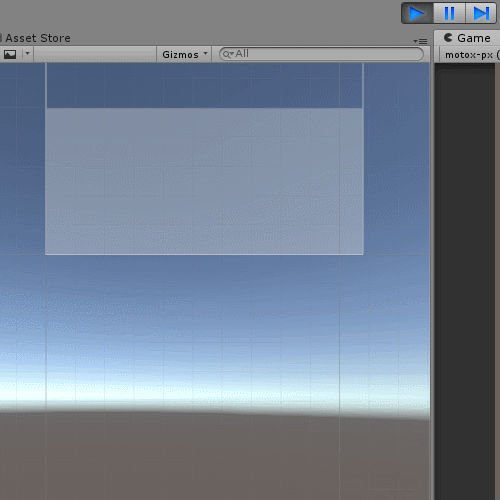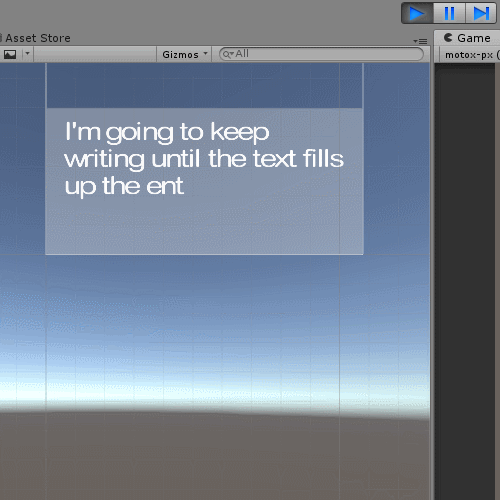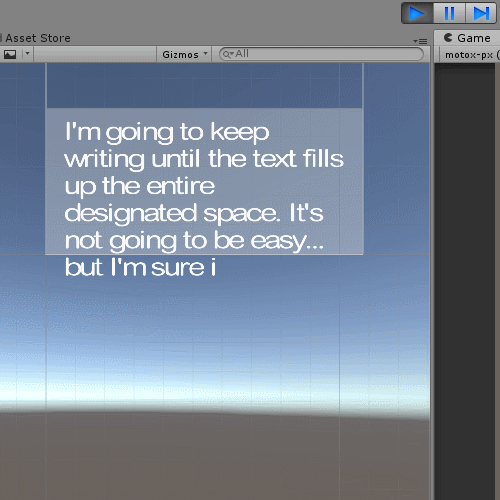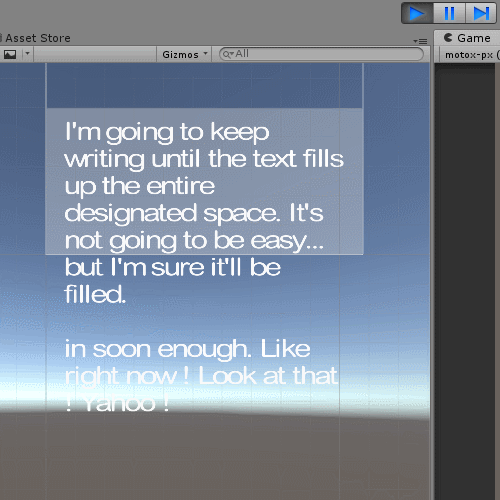
Above attached gif demonstrates the effect. (alternative link here: https://i.imgur.com/PYTdVmI.gif)
{kind=link}
While a line of text from the Dialogue Sample (with readout controls script attached) is being read, pausing the game in the editor does not halt the readout. While the graphics and sound halt, it is still being read normally in the background. Unpausing the game in the editor will update and the graphics will load, being at the expected 'point' as if the readout had been continuous. Everything else behaves as expected.