
Yooo!!
A member registered Aug 29, 2019 · View creator page →
Creator of

Play as Marol who got teleported mysteriously during a conference meeting.
Interactive Fiction
Recent community posts
Doodle Studio 95! community » New features and suggestions · Created a new topic A shame this has been abandoned.
I've been getting some errors. Both devices are Windows 10.
On the computer with a 1.60 GHz processor I'm getting "Fatal error detected. Failed to execute script opencvtuber". It could be because the program is too extensive for the hardware so I tried my other computer.
On that one it does start. However the character and background load at an angle and partially out of the window. It doesn't respond well to the camera even with good lighting and even when I tilted the device the character and background continued to be at an angle.
Upon exiting the program, I get the following error:
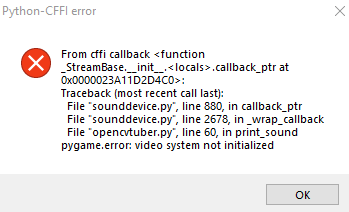
I think the program has potential though. Could there be a way to lock the character portrait in place and only react to sound or voice? I'm thinking of something like Star Fox.
Also is there a way to change the background's color or anything? Is there a menu key I may have missed?