
For those who are with me this far, I did the analysis of letter distribution and the results are a bit tricky to work with. The image below shows a variety of letter choices for the three anchor points, and the true probability for each plain/but/and/event outcome based on a 10k English (most popular) word list. To read the charts, look at first top one. This represents our initial starting point, HOV, which purports to have a decent separation of segments, giving a wrinkle 52% of the time and an event 15% of the time. However upon analysis of which letters are actually common, the true percentages shift to 3% chance of events and everything else more or less even. This didn't come as a shock to me, as it was clear that the event segment included X and Z which would naturally be less utilized.
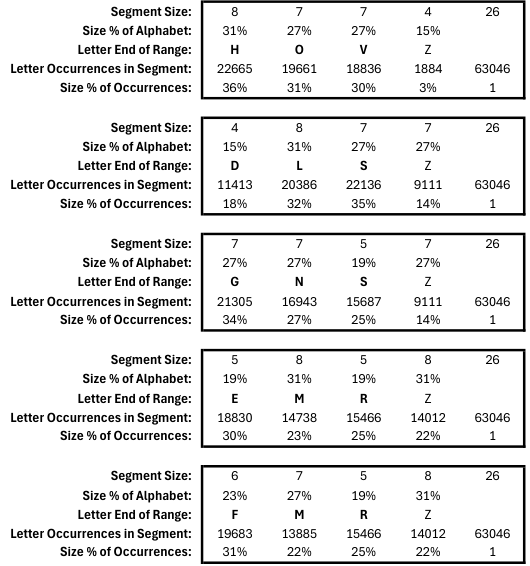
However thanks to a sharp difference between D and E (the latter of course being the most common letter) I'm really kind of stuck either setting plain outcomes at 18% or 30% but nothing in between. That's probably fine. EMR is not a bad choice, but that makes events a bit too spicy. My favorite is probably GNS as anchors, creating a 34% chance of a plain result, a 14% chance of an event, and 52% chance of an and/but complication, skewing ever slightly to the and.
Now as for a mnemonic, GNS has some possibilities:
- GAINS
- GENES
- GENUS
- Granular Narrative Spectrum
- Guided Narrative Scale