
Good question!
I tried quickly adding it as that’s largely the same code as the 64-bit one, and turns out that it’s hardly faster:
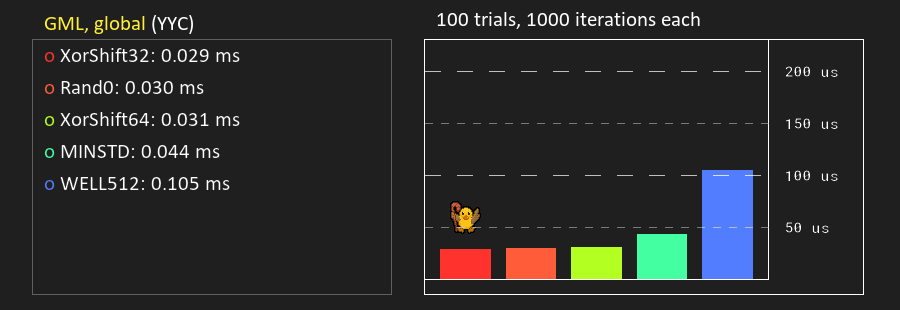
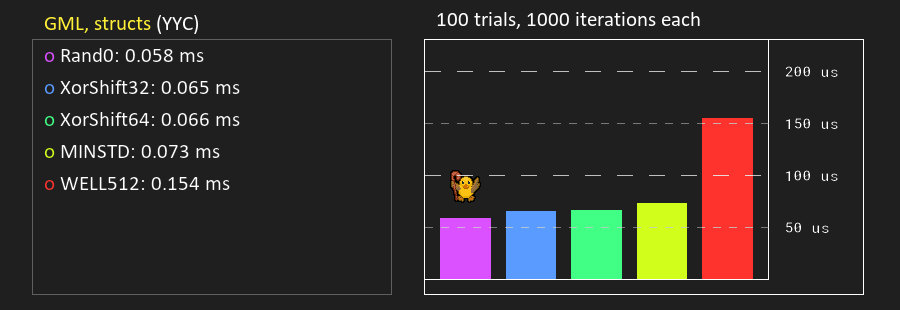
And for some reason it is slower if you put the whole PRNG in a macro:
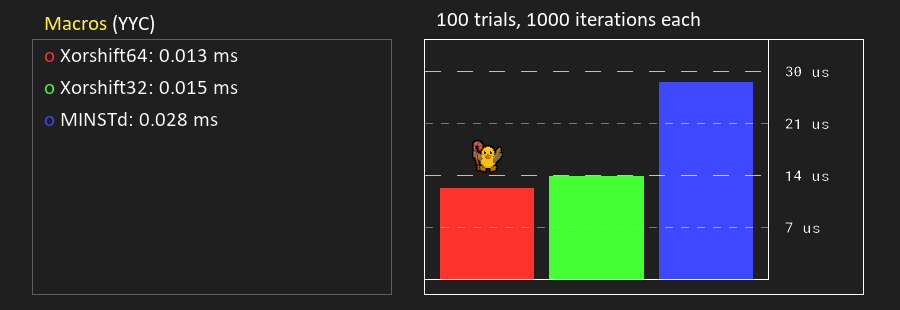
I was expecting it to be slightly faster since you don’t have to do the ordeal with manually shifting the sign bit, but I didn’t notice that you have to do & $FFFFFFFF after both << operations to simulate a 32-bit register.
If you are using Julian’s implementation of 32-bit Xorshift specifically, you’ll want to update to the latest commit because Julian didn’t previously notice this either.
Either way, I included it in the test project, but I see little reason to use the 32-bit version over the 64-bit one.
Another thing to consider with PRNGs (or other relatively small functions) is the way you implement them.
Putting the whole thing in a macro that you use instead of a function call is the fastest and global scripts with global variables are faster than method calls on constructors, but having methods call other methods also costs! So
function Xorshift32(_state) constructor {
state = _state;
static value = function() {
state ^= (state << 13) & $FFFFFFFF;
state ^= (state >> 17);
state ^= (state << 5) & $FFFFFFFF;
return state / 4294967296.0;
}
static float = function(_max) {
return value() * _max;
}
}
will be slower than
function Xorshift32(_state) constructor {
state = _state;
...
static float = function(_max) {
state ^= (state << 13) & $FFFFFFFF;
state ^= (state >> 17);
state ^= (state << 5) & $FFFFFFFF;
return state / 4294967296.0 * _max;
}
}
In my code I deal with this by auto-generating the scripts from Haxe source code (and have the Haxe compiler inline everything so that no function goes more than one call deep)