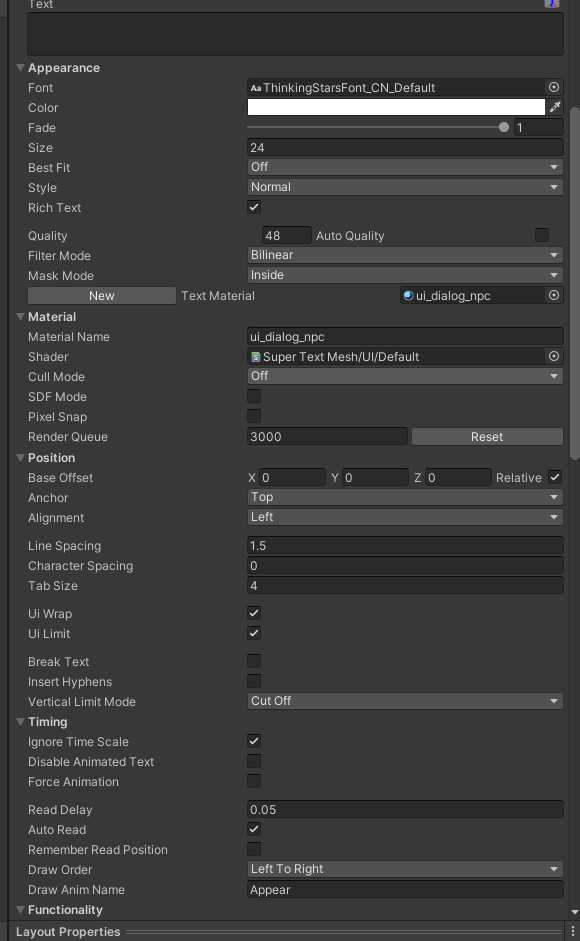
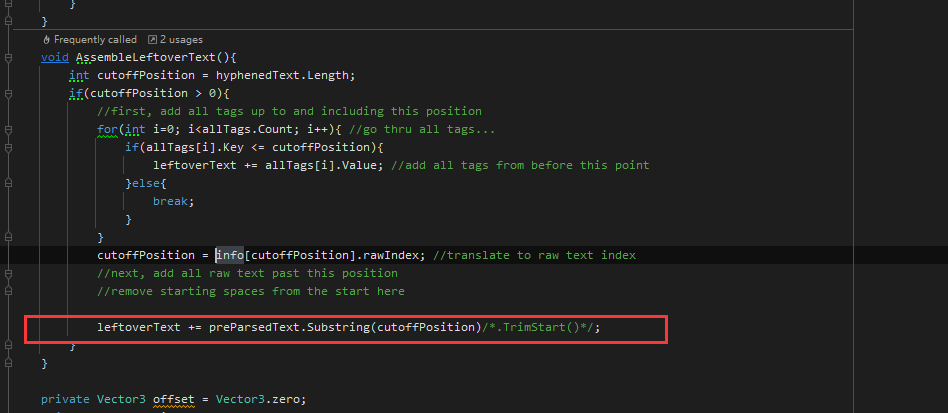
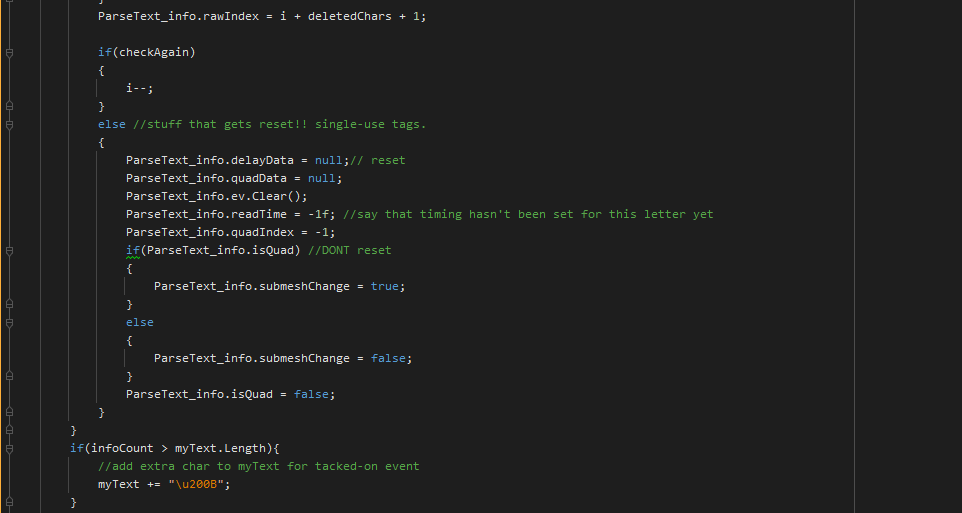
Time is urgent, hope to solve it soon, thank you!
text is :
ホ<u=200B>ッ<u=200B>ツ<u=200B>先<u=200B>生<u=200B>は<u=200B>昔<u=200B>こ<u=200B>こ<u=200B>の<u=200B>名<u=200B>誉<u=200B>市<u=200B>民<u=200B>の<u=200B>称<u=200B>号<u=200B>を<u=200B>取<u=200B>っ<u=200B>た<u=200B>こ<u=200B>と<u=200B>も<u=200B>あ<u=200B>っ<u=200B>た<u=200B>ん<u=200B>だ<u=200B>っ<u=200B>た<u=200B>な…<u=200B>え<u=200B>ー<u=200B>と、<u=200B>あ<u=200B>れ<u=200B>は<u=200B>何<u=200B>年<u=200B>前<u=200B>の<u=200B>こ<u=200B>と<u=200B>だ<u=200B>っ<u=200B>た<u=200B>か<u=200B>な<u=200B>?<u=200B>覚<u=200B>え<u=200B>て<u=200B>は<u=200B>い<u=200B>る<u=200B>ん<u=200B>だ<u=200B>が、<u=200B>具<u=200B>体<u=200B>的<u=200B>な<u=200B>こ<u=200B>と<u=200B>が<u=200B>思<u=200B>い<u=200B>出<u=200B>せ<u=200B>な<u=200B>い…<u=200B>も<u=200B>う<u=200B>年<u=200B>だ<u=200B>な。
inspector :