


The latest version of FV is the one to use as it still runs older library files just fine...actually, better. You can get the older library file from 4.37 on the FV discord. I recommend using the latest version of the plugin also as it too works better with the older library file.
A member registered Sep 07, 2021 · View creator page →
Creator of
Recent community posts
From a hardware standpoint, nose down and nose up are on the same axis, just half on one side, half on the other. The FoxVox Parser plugin automatically uses the range 0-45% for one side, and 65-100% for the other by default, leaving a small 10% dead-band in the middle (It may actually be 20%...I don't recall offhand).
I'm not familiar with the TM TARGET HID device, but you can manually set the desired axis range within FoxVox by clicking the controller button next to it and setting whatever range you want it to be.
For this command on the VCC, although the input is analog, it is working as a discrete on/off switch - toggling on and off as the axis enters and leaves the specified range.
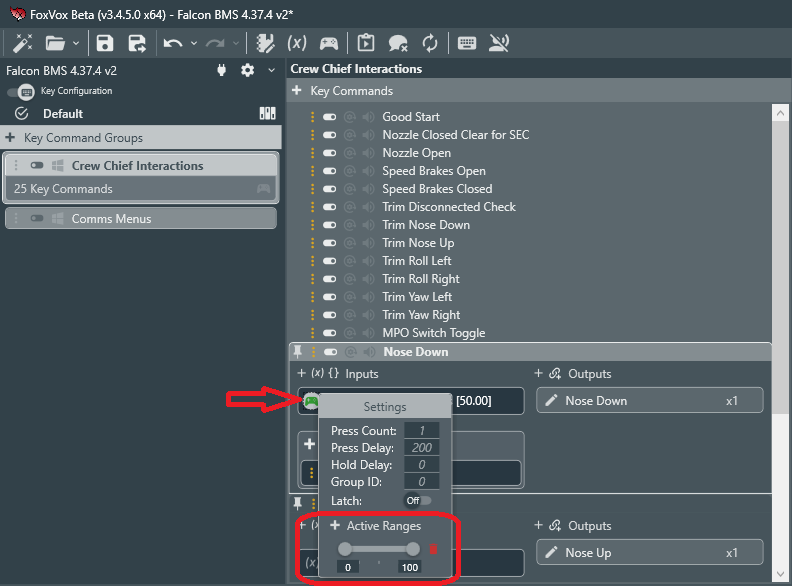
If you're using short single phrase commands like that, you might try experimenting with the Eager Recognition setting which is designed for speeding up commands for that kind of game. It will fire off a command the instant it recognizes a match when it's on without waiting for the entire phrase to complete.
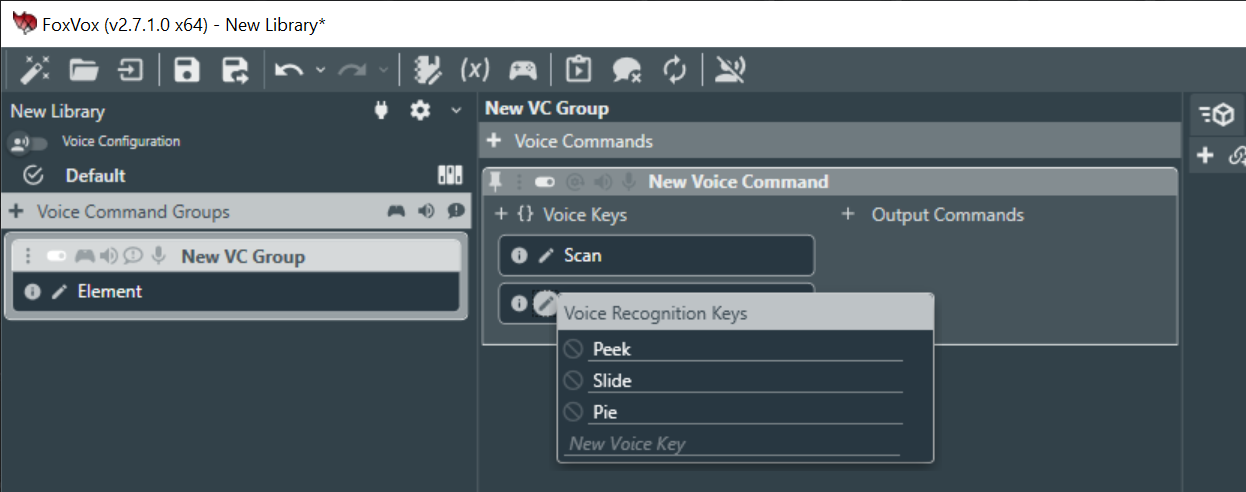
Are the outputs really supposed to be the same for Scan 1, 2 & 3? If not, then they have to be on separate commands. If so, then I think maybe this is what you're after? This allows for any of these phrases to work:
"Element Scan Peek"
"Element Scan Slide"
"Element Scan Pie"
I'm sorry if I'm misunderstanding you...
FoxVox Falcon BMS Libary v4.37.3 Update comments · Replied to xKoc0 in FoxVox Falcon BMS Libary v4.37.3 Update comments
Just to confirm, you can switch between voice and key configurations at the upper left (just below the library name) and you must enable key recognition as shown here:

Just so you are aware, voice commands can only be triggered by voice, however key commands will trigger based on not only key input but also trigger on conditions, which is why they reside there for the VCC. If you have enabled key commands and everything is triggering but you still don't hear anything, check to see if you have windows media player installed or disabled. They will also play if an alternative player has been set up in Windows, but you may experience issues there if they can't open through the Windows shell command.
Edit: Also make sure the VCC files which contain the audio files are present in the subfolder with the library...sometimes it's the little things that can get overlooked.