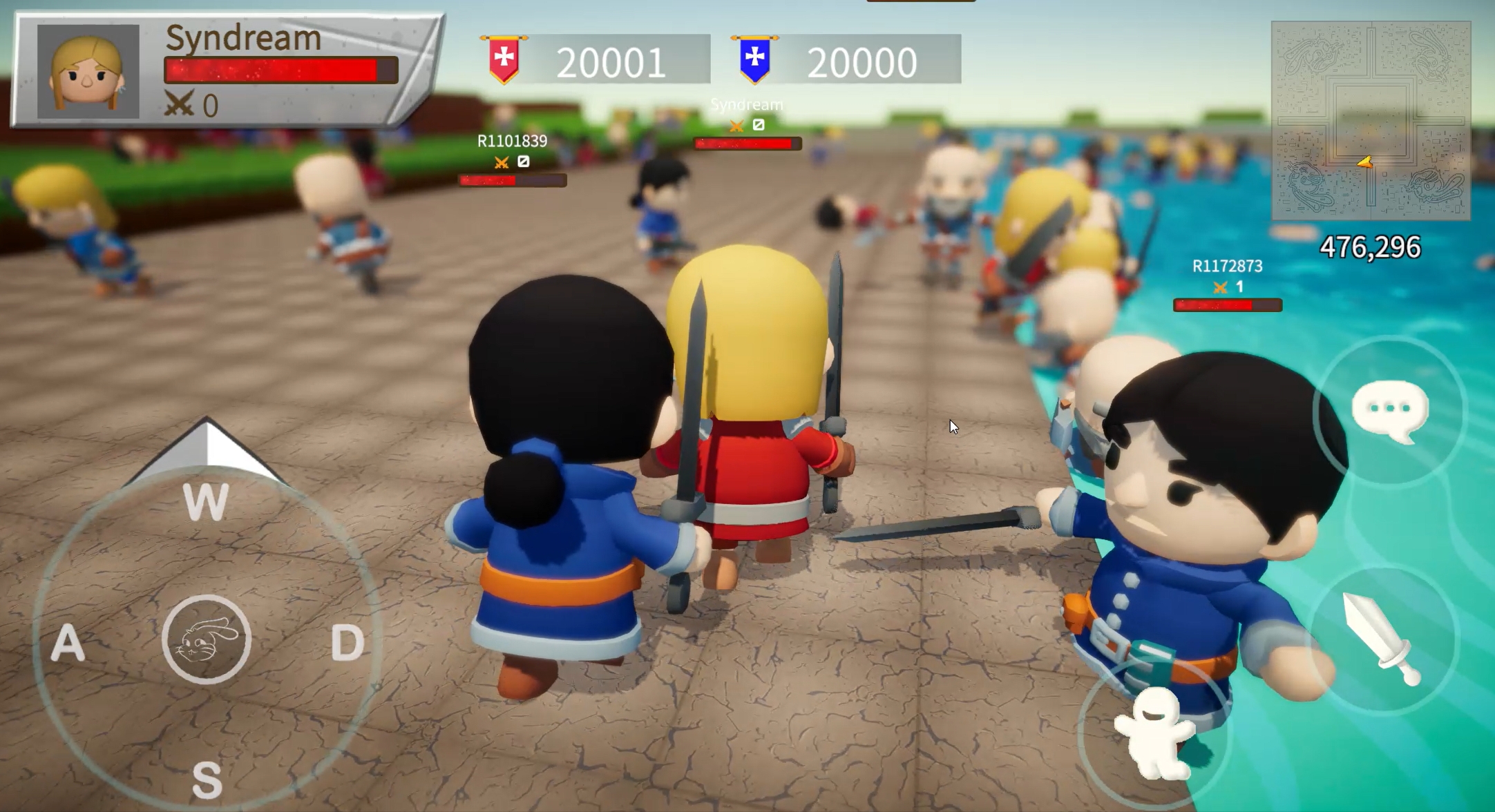
This engine completed its core features in 2024, and its biggest highlight is probably the ability to support tens of thousands — even millions — of players interacting in real time.
By March 2025, we had already finished our global test. But the content was pretty limited — players could run around, say hi to each other, and chat. That’s about it.
This time, we want to expand the gameplay.
So! I’ve decided to divide players into two factions. They’ll be able to fight each other, and the more enemies they defeat, the more military points they earn. Players can also see which areas on the map are controlled by their faction.
The goal here is to prove that large-scale MMOs with tens of thousands of players aren't some impossible dream. Scaling player numbers shouldn't be a problem — in fact, the more players there are, the better your faction can grow, right?
If every channel or world keeps capping the number of online players, what happens when player counts drop? There's no one left to play with. That’s the real issue.
Syndream is here to break that limitation.
A true MMO should be a scalable world where players can join freely, without artificial limits.