Hi Iocchi, are you using Vocal Slice regularly still? Most of the other users seem to be translating english so I wonder how your experience has been with more use?
A member registered Feb 19, 2025 · View creator page →
Creator of

Find and extract voice lines from audio files. Perfect for game devs and content creators.
Recent community posts
Hi locchi, thank you for your interest in VocalSlice. The program does have the ability to transcribe and slice Japanese! However I noticed when testing today that there were some issues displaying Japanese and other international characters in the search box and transcription editor.
I will release a fix for this today (VocalSlice v0.1.9) which will fully support rendering of Japanese characters. I would really appreciate you trying it out and providing feedback.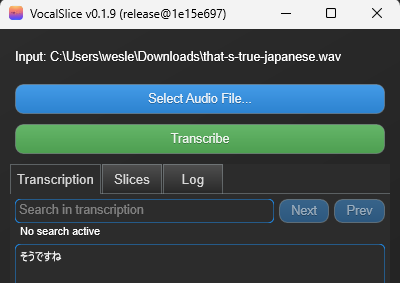
VocalSlice should be great for slicing phrases/sentences out of larger recordings, but may struggle with precision if you try slicing letters/syllables within words. You can try changing your selections and attack/release times in settings to add buffering around what you are trying to slice if you have issues with accuracy.