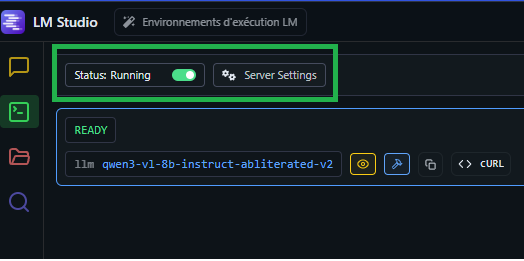
Try using the desktop app and not the web-app or vice versa
A member registered Oct 21, 2025 · View creator page →
Creator of

An AI companion that sees your screen, talks back, remembers you. Build any character: anime, waifu, with voice cloning.
Recent community posts
Desktop Companion — AI Desktop Pet for Windows comments · Replied to kanmuru69 in Desktop Companion — AI Desktop Pet for Windows comments
Desktop Companion — AI Desktop Pet for Windows comments · Replied to Apellon in Desktop Companion — AI Desktop Pet for Windows comments