I've create a custom box scene that uses a LLM loaded in LM Studio to generate a description of the hidden content.
Video showcase using images by MIAOKA on civitai :
How to use it
1) Download the file "llm_description.box.tscn" here or here and put it inside your CUSTOM_DATA folder.
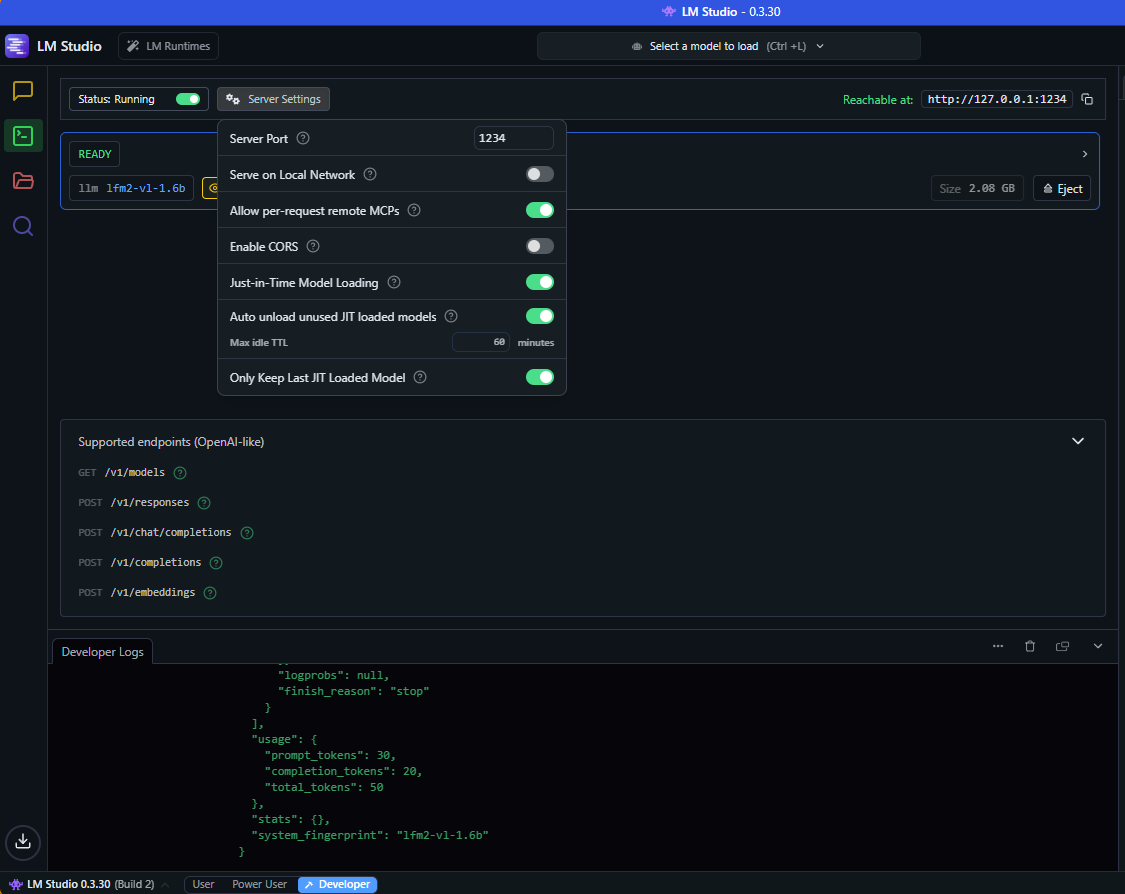
2) Start LM Studio. (You can install it from here : https://lmstudio.ai)
Install and load a vision model. (lmf2-vl is fast. qwen2.5-vl-nsfw can allow spicy descriptions.)
Start the server. (*)
3) Start Hotscreen.
Add a filter -> Mods -> Box scene
Edit filter -> Select custom scene -> Open the file "llm_description.box.tscn"
The "mod" is very simple. It's only a text file loaded like a box. It doesn't reference any Hotscreen scripts/variables, making it easy to modify in Godot (or by an AI chatbot). There are variables at the top to change the prompt, color, etc.
I think this mod illustrates the power of Hotscreen's modding capabilities well. I hope you will find it cool too. 😊
(*) Here are my settings in LM Studio which should be the default ones :