This tutorial will explain how to use the cross-platform ML framework MediaPipe launched by Google to play with small things. I directly use the MediaPipeUnityPlugin that has perfectly integrated MediaPipe for the first experience of gesture recognition. First, after cloning the repos, a series of installation and building (see Installation Guide), and install the appropriate version of Unity and plugin.
Unity 2021.1.7f1
MacBookPro 13-inch 2019 (MacOS 10.15.4)
The build version of the cpu used here:
build.py build --desktop cpu -v
After the establishment is successful, you should see a message similar to the following:
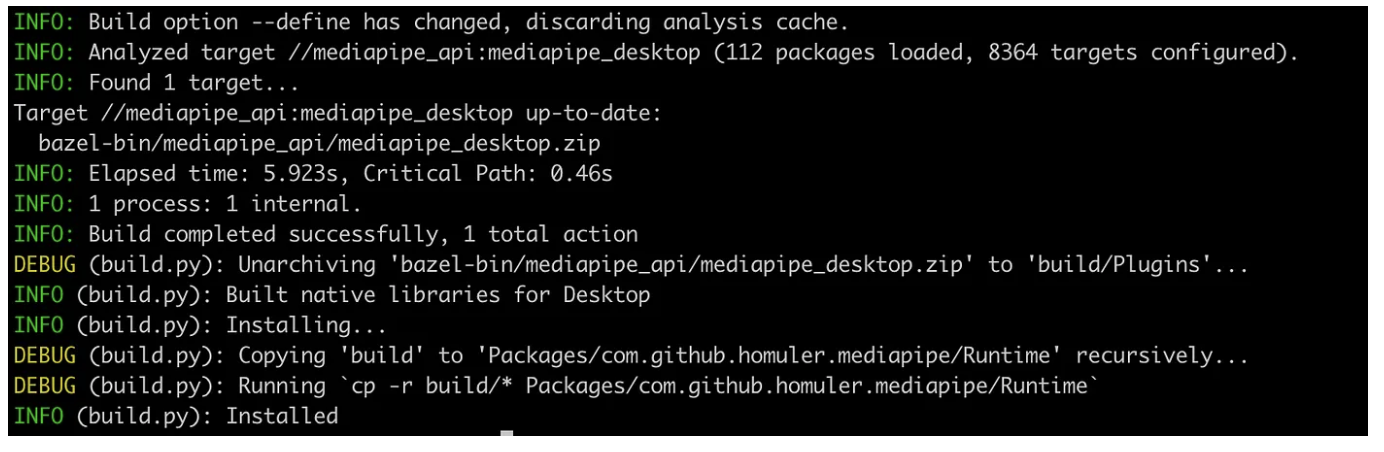
Then you can open the MediaPipeUnityPlugin project to execute the demo scene: (Assets/Mediapipe/Samples/Scenes/Face Mesh)
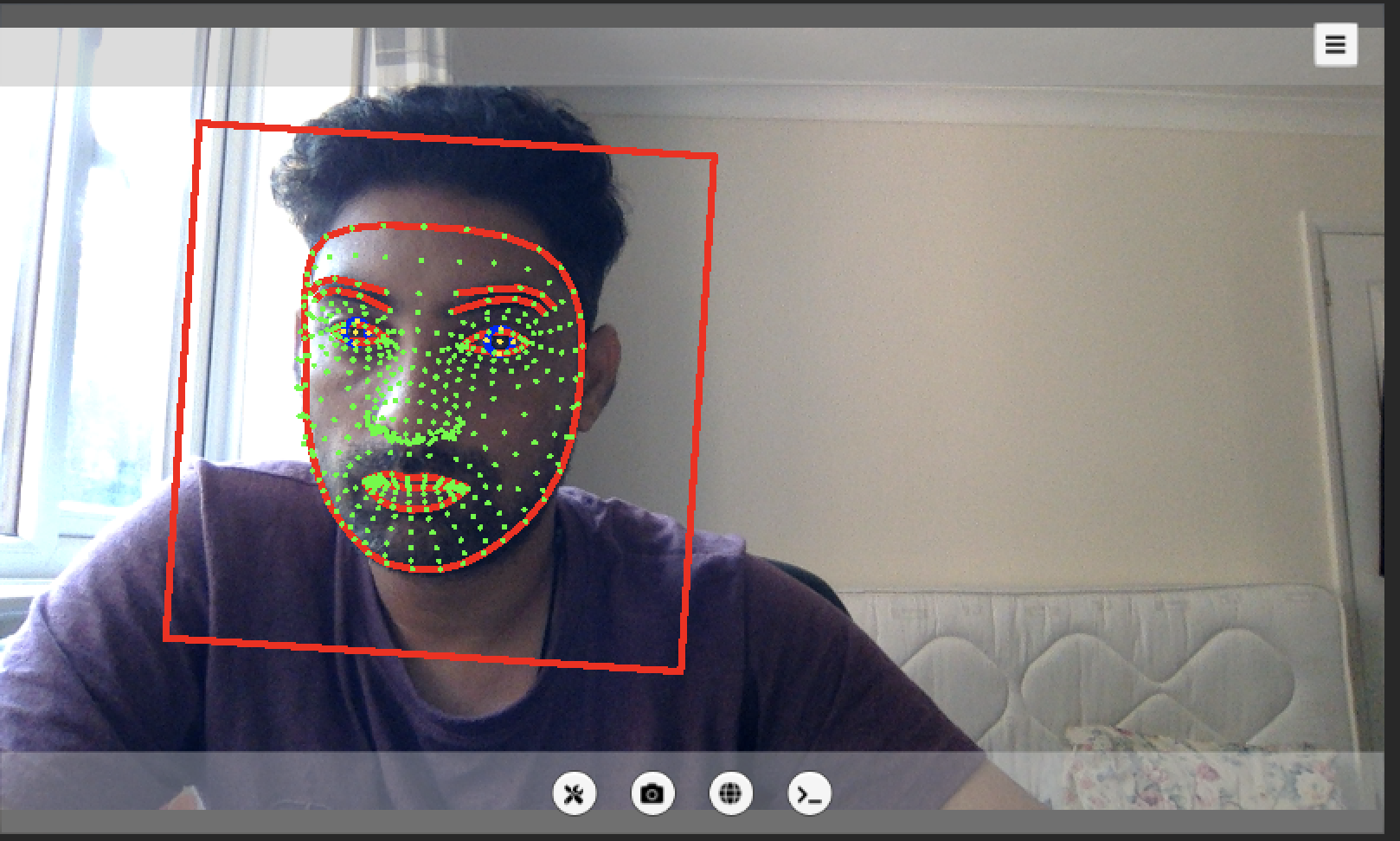
If you can successfully see the webcam screen and the preset FACE Detection effect, then congratulations, you have successfully completed the preparation work here.
Architecture
Next, we will use the scripts and framework provided by MediaPipeUnityPlugin to write our own scenarios. The categories expected to be used are:
class GestureTrackingDirector : MonoBehaviour { }
class GestureTrackingGraph : HandTrackingGraph { }
class HandState { }
class GestureAnalyzer { }
GestureTrackingDirector is our root controller. It is responsible for obtaining webcam images through WebCamScreenController and then passing them to GestureTrackingGraph for analysis. After that, we convert the analyzed hand bone information into HandState, and then feed it to GestureAnalyzer to judge gestures.
The scene object configuration is as follows:
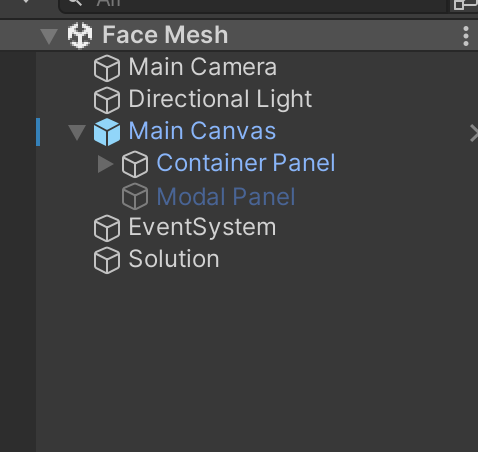
Models
The Face Landmarker uses a series of models to predict face landmarks. The first model detects faces, a second model locates landmarks on the detected faces, and a third model uses those landmarks to identify facial features and expressions.
The following models are packaged together into a downloadable model bundle:
Face detection model: detects the presence of faces with a few key facial landmarks.
Face mesh model: adds a complete mapping of the face. The model outputs an estimate of 478 3-dimensional face landmarks.
Blendshape prediction model: receives output from the face mesh model predicts 52 blendshape scores, which are coefficients representing facial different expressions.
The face detection model is the BlazeFace short-range model, a lightweight and accurate face detector optimized for mobile GPU inference. For more information, see the Face Detector task.
The image below shows a complete mapping of facial landmarks from the model bundle output.
You must first modify the FetchNextHandTrackingValue and RenderAnnotation methods in HandTrackingGraph from private to protected so that GestureTrackingGraph can be called.
public class GestureTrackingGraph : HandTrackingGraph
{
public delegate void GestureTrackingValueEvent (HandTrackingValue handTrackingValue);
public event GestureTrackingValueEvent OnHandTrackingValueFetched = (h) => { };
public override void RenderOutput (WebCamScreenController screenController, TextureFrame textureFrame) { var handTrackingValue = FetchNextHandTrackingValue ();
RenderAnnotation (screenController, handTrackingValue); screenController.DrawScreen (textureFrame);
OnHandTrackingValueFetched (handTrackingValue); }
}
Then we want to judge the opening and closing state of each finger through the NormalizedLandmarkList (hand bone information) in the returned data of HandTrackingValue, so we add a new category HandState to handle it, and express the state of each finger through enum FingerState individual status:
[Flags]public enum FingerState
{
Closed = 0,
ThumbOpen = 1,
IndexOpen = 2,
MiddleOpen = 4,
RingOpen = 8,
PinkyOpen = 16,
}For information about NormalizedLandmarkList, please refer to the official document or the image below:

public class HandState
{
[Flags] public enum FingerState {…}
public delegate void HandStateEvent (FingerState previousState, FingerState currentState);
public event HandStateEvent OnStateChanged = (p, c) => { };
FingerState m_FingerState;
public void Process (Mediapipe.NormalizedLandmarkList landmarkList)
{ FingerState fingerState = FingerState.Closed; /* Analyse Fingers */
if (m_FingerState != fingerState)
{ OnStateChanged (m_FingerState, fingerState);
m_FingerState = fingerState;
}
}
}As for how to judge the opening and closing of fingers? Here we simply use a very simple geometric position to analyze, and judge the right hand (the thumb needs to judge whether the palm or the back of the hand is facing the camera):
It's a pity that the assumption here is that the hand is placed upright. If it is reversed, the judgment will be wrong (palm facing y+, fingers facing y-). If you want to solve the problem of rotation, you can use the three points of 0, 5 and 17 as For the reference point, first calculate the rotation matrix of the palm, and then convert all other points into positive pendulum positions, and then do
In this way, the opening and closing of each finger can be easily judged. We can use the opening and closing to combine different gestures. The following is GestureAnalyzer
public static class GestureAnalyzer
{
public static MeaningfulGesture Analyze (this HandState.FingerState state)
{ /* Analyze Gesture */}Define a meaningful gesture MeaningfulGesture:
public enum MeaningfulGesture
{ None, Hold, One, Two, Three, Four, Five, Six, Seven, Eight, Nine}The next step is very simple. For example, Seven is FingerState.ThumbOpen | FingerState.IndexOpen, and Eight is FingerState.ThumbOpen | FingerState.IndexOpen | FingerState.MiddleOpen:
After all these are ready, we can get everyone around through GestureTrackingDirector!
There is no special selection function of WebCamTexture.devices here, and the first webcam captured is used directly.
Gesture analysis is performed only for the first detected hand.
References
Did you like this post? Tell us

Leave a comment
Log in with your itch.io account to leave a comment.
There is no FetchNextHandTrackingValue in HandTrackingGraph ???
Can you please provide your source code? Im really confused.
Thanks