🧑🔬 Join us for this month's alignment jam! Get answers to all your questions in this FAQ. See all the starter resources here. Go to the Discord (important) and GatherTown here.

This month's alignment jam is about TESTING THE AI! Join to find the most interesting ways to test what AIs do, how fair they are, how easy they are to fool, how conscious they become (maybe?), and so much more.
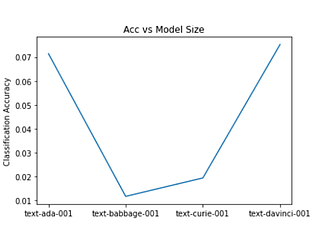
We provide you with some State-of-the-Art resources to test all the newest models and you can focus on neural network verification, creating fascinating datasets, interesting reinforcement learning agents, deep Transformer interpretable feature extractions, safe RL agents in a choose-your-own-adventure games and red teaming the heck out of current models.

Create a user on the this itch.io website and click Join jam. We will assume that you are going to participate and ask you to please cancel if you won't be part of the hackathon.
You submit by following the instructions on the Alignment Jam page.
Everyone will help rate the submissions together on a set of criteria that we ask everyone to follow. You receive 5 projects that you have to rate during the 4 hours of judging before you can judge specific projects (so we avoid selectivity in the judging).
Each submission will be evaluated on the criteria below:
| Criterion | Description |
|---|---|
| Safety | How good are your arguments for how this result informs the longterm alignment and understanding of neural networks? How informative is the results for the field of ML and AI safety in general? |
| Benchmark | How informative is this as a benchmark for AI or ML systems? Does it inform the field for benchmarks on AI? |
| Novelty | Have the results not been seen before and are they surprising compared to what we expect? |
| Generality | Do your research results show a generalization of your hypothesis? E.g. if you expect language models to overvalue evidence in the prompt compared to in its training data, do you test more than just one or two different prompts and do proper interpretability analysis of the network? |
| Reproducibility | Are we able to easily reproduce the research and do we expect the results to reproduce? A high score here might be a high Generality and a well-documented Github repository that reruns all experiments. |
Check out the continually updated inspirations and resources page on the Alignment Jam website here. See also continually updated ideas for projects on aisi.ai.
No submissions match your filter