We're currently live! To participate, use this report template to submit your projects to this page. Check out the live stream from Friday as well.
---
Machine learning is becoming an increasingly important part of our lives and researchers are still working to understand how neural networks represent the world.

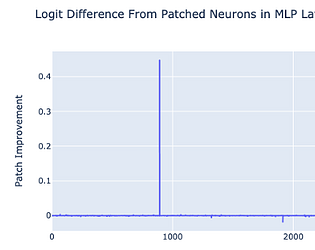
Mechanistic interpretability is a field focused on reverse-engineering neural networks. This can both be how Transformers do a very specific task and how models suddenly improve. Check out our speaker Neel Nanda's 200+ research ideas in mechanistic interpretability.
Join us in this iteration of the Alignment Jam research hackathons to spend 48 hour with fellow engaged researchers and engineers in machine learning on engaging in this exciting and fast-moving field!
Join the Discord where all communication will happen. Check out research project ideas for inspiration and the in-depth starter resources.

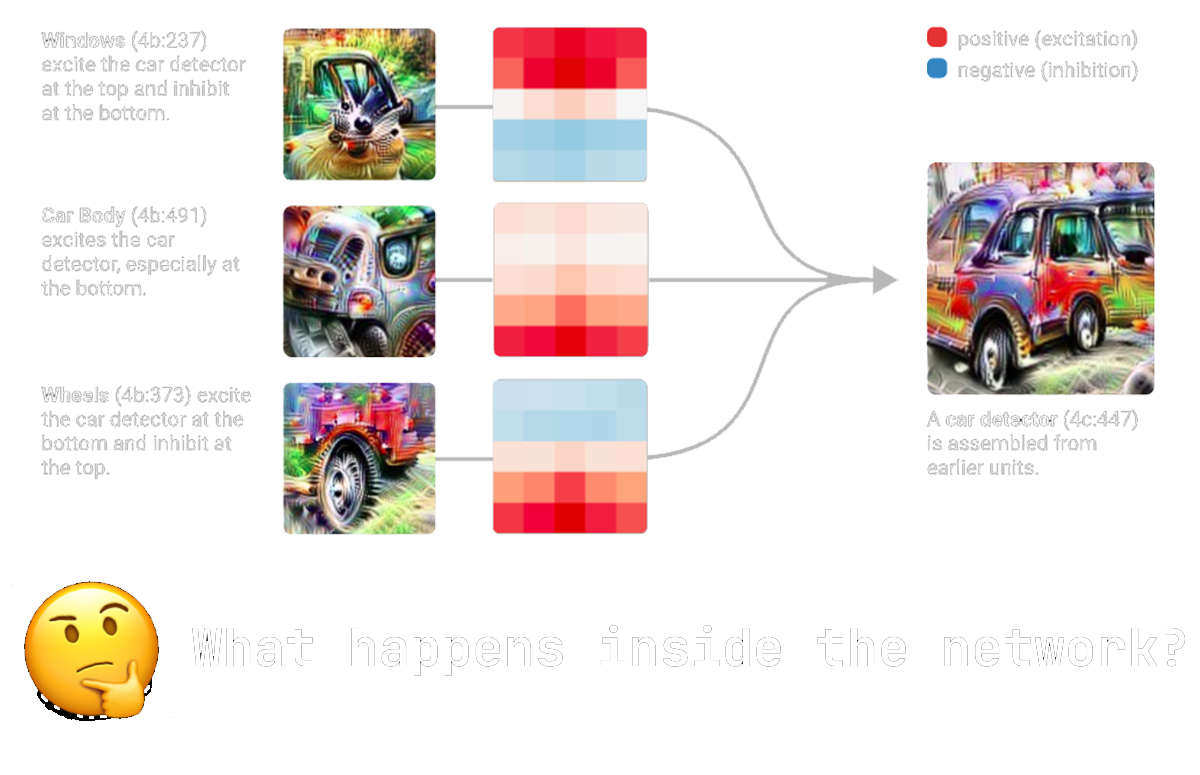
Using mechanistic interpretability, we will dive deep into how neural networks think and do. We work towards reverse-engineering the information processing of artificial intelligence!
We provide you with the best starter templates that you can work from so you can focus on creating interesting research instead of browsing Stack Overflow. Check the resources out here. You're very welcome to check out some of the ideas already posted!
The schedule runs from 5PM CET / 8AM PST Friday to 7PM CET / 10AM PST Sunday. We start with an introductory talk and end with an awards ceremony. Join the public ICal here.

If you are part of a local machine learning or AI safety group, you are very welcome to set up a local in-person site to work together with people on this hackathon! We will have several across the world (list upcoming) and hope to increase the amount of local spots. Sign up to run a jam site here.
You will work in groups of 2-6 people within our hackathon GatherTown and in the in-person event hubs.
Everyone who submits projects will review each others' projects on the following criteria from one to five stars. Informed by these, the judges will then select the top 4 projects as winners!
| ML Safety | How good are your arguments for how this result informs alignment and understanding of neural networks? How informative are the results for the field of ML and AI safety in general? |
| Mechanistic Interpretability | How informative is it in the field of mechanistic interpretability? Have you come up with a new method or found completely new results? |
| Novelty | Have the results not been seen before and are they surprising compared to what we expect? |
| Generality | Do your research results show a generalization of your hypothesis? E.g. if you expect language models to overvalue evidence in the prompt compared to in its training data, do you test more than just one or two different prompts and do proper interpretability analysis of the network? |
| Reproducibility | Are we able to easily reproduce the research and do we expect the results to reproduce? A high score here might be a high Generality and a well-documented Github repository that reruns all experiments. |
No submissions match your filter