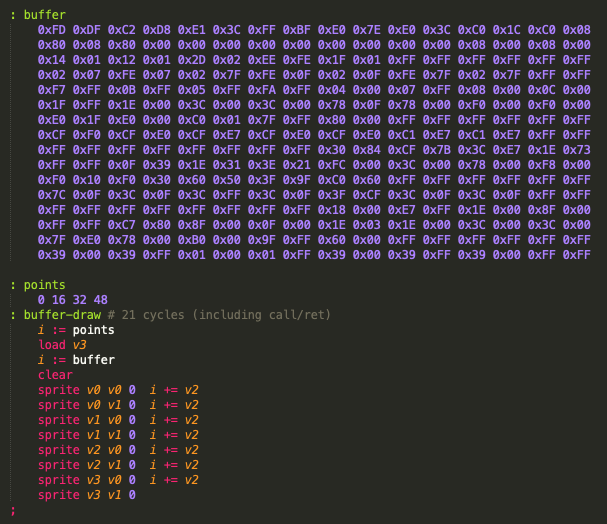
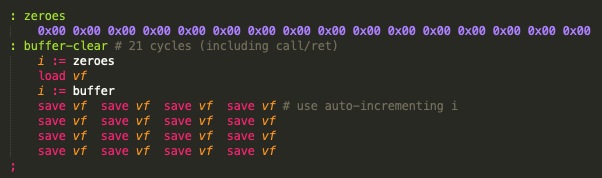
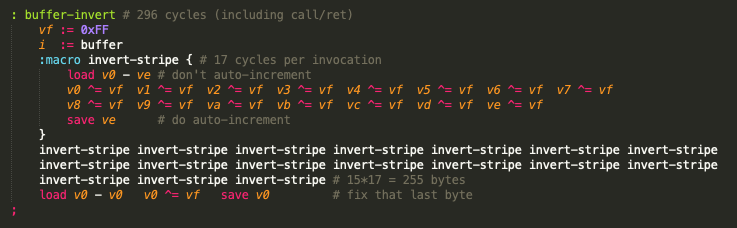
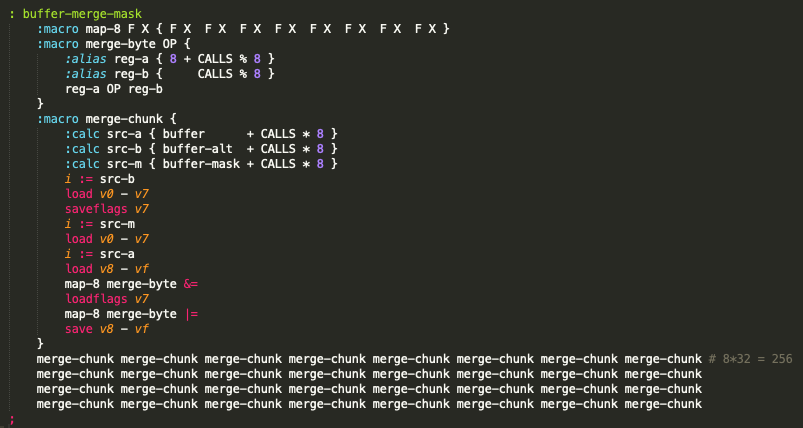
I was thinking about writing a game with a couple of "layers" (in colour, so I can't use the "each plane is sort of a layer" trick). Only having XOR for sprite drawing is a little limited for my purpose, so this evening I wrote a few rendering algorithms that operate on a buffer in memory (clear buffer, AND/OR sprite to buffer, render buffer to the screen, that sort of thing).
Now here's the thing: it's working just fine, but it's freakishly slow. Even on "ludicrous speed" :P Especially the sprite rendering to the buffer seems to be way too slow to fill the screen in a reasonable time (in hires mode especially).
Hence my question: Has anyone here ever tried to do buffered rendering? And if so, was that a success? Is my code just really silly and unoptimized, or is it just kinda outside of the reach of the platform?